前几天看到微博上大家讨论县城名字:http://weibo.com/1444865141/EjcmoaykB
一时好奇,就把官方数据拿来看了一下。(2016年9月中华人民共和国县以上行政区划代码)
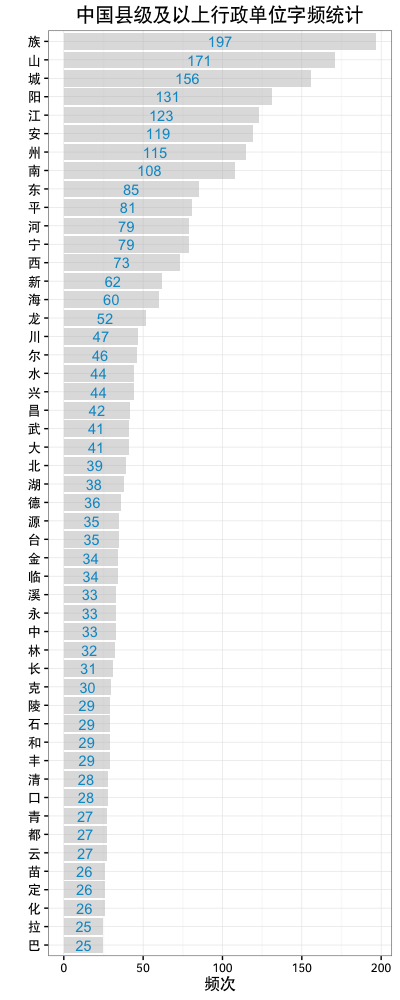
全部用来命名的只有1228个字,而相较于新华字典一般收录的八千到1万字,覆盖面其实挺小的。
不出意外的,这个字频分布呈现快速下降的长尾分布。看一下这个数据,还是蛮有意思的。
- 第一名的“族”主要是有各种少数民族自治行政区划的存在。
- 如果不看这个,则最受大家喜欢的就是“山”,“城”,“阳”,“江”,“安”,“州”。
- 四个方向中,排序为“南”>“东”>“西”>“北”。
- 地势描述成为了命名的主力词:山、江、河、海、川、湖、溪、林等。
- 五行排名如下:水>金>土>木,然后没有火!看来全国人民都痛恨火灾。是不是和马伯庸提到的“雪”同理?大家都讨厌灾害。
这里贴一下前50高频词。
完整的字频统计在这里: 中国县级及以上行政单位字频统计.txt
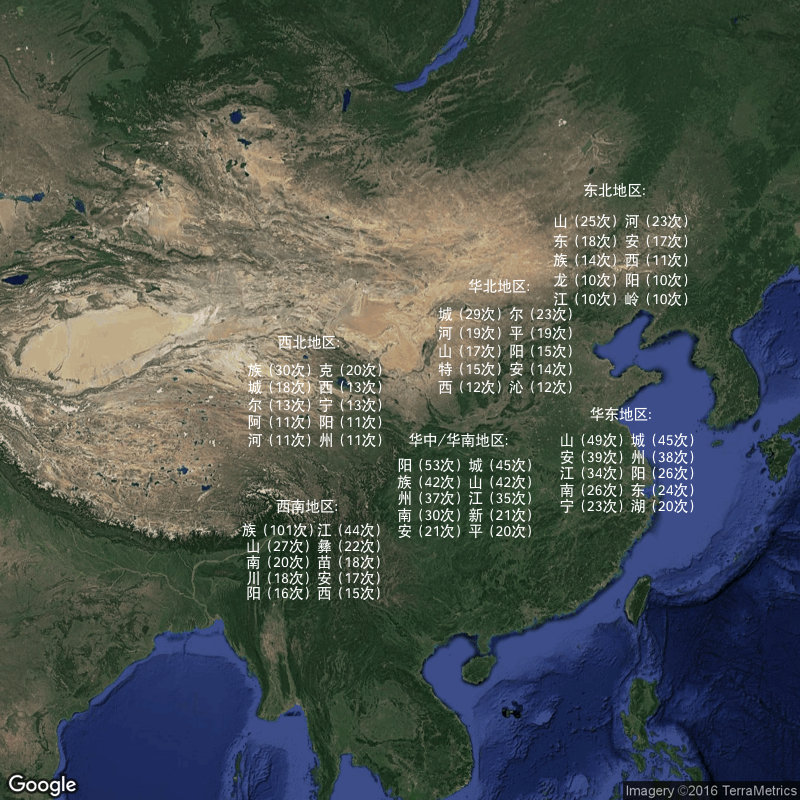
然后我们分区域来看一下各个区域特征。因为港澳台地区没有太多数据,所以我们只分析六大区域:华北、东北、华东、华中/华南、西南、西北。
- 地势:除了西北地区以外,其他五个地区特别喜欢“山”。此外,东北常用“江河岭”,华北、西北常用“河”,华中/华南常用“江”,华东常用“江湖”,西南常用“江川”。
- 四个方向:东北地区喜欢“东西”,华北地区喜欢“西”,华东地区喜欢“东南”,华中/华南常用“南”,西北常用“西”,西南常用“西南”。
- 东北地区、西北地区、华南地区多有少数民族,故而地名含有民族名称。
全部数据下载:
原始数据:
分析脚本:
town_name <- read_csv("~/Documents/town_name.csv")
names(town_name) = c("code","name")
town_name$name_s = gsub("市$|区$|县$|旗$|自治.*?$|盟$|省$","",town_name$name)
unique_character = unlist(strsplit(town_name$name_s,split = ""))
character_freq = as.data.frame(table(unique_character))
library(dplyr)
character_freq = character_freq %>%
arrange(Freq) %>%
mutate(rank = 1:nrow(character_freq))
write.csv(character_freq, file = "character_freq.csv", row.names = F)
library(ggplot2)
top_50 = character_freq %>% filter(Freq >= 25)
ggplot(top_50, aes(x = as.factor(rank), y = Freq)) +
geom_bar(stat="identity", alpha = 0.5, fill = "grey")+
coord_flip()+
theme_bw(base_family = "Hei") +
scale_x_discrete(labels = top_50$unique_character) +
xlab("") +
geom_text(aes(label = Freq, y =Freq/2 ), color = "deepskyblue3") +
ylab("频次")+ggtitle("中国县级及以上行政单位字频统计")
#五行
character_freq %>% filter(unique_character %in% c("金","木","水","火","土"))
#省
town_name$province = substr(town_name$code, 1,2)
town_name$region = substr(town_name$code, 1,1)
unique_prov = town_name %>%
filter(grepl("0000",town_name$code))
char_by_prov = lapply(unique_prov$province, function(x) {
prov = subset(town_name,province==x)
chars = unlist(strsplit(prov$name_s,split = ""))
freq_prov = as.data.frame(table(chars))
freq_prov$rank = rank(-freq_prov$Freq, ties.method = "first")
freq_prov$prov = x
return(freq_prov)
})
char_by_prov = do.call(rbind, char_by_prov)
names(char_by_prov)
ggplot(char_by_prov %>% filter(rank<=5 & chars != "族" & ! prov %in% c(82,81)), aes(x= rank, y = Freq)) +
geom_bar(stat="identity", alpha = 0.3)+
facet_grid(name~.)+
theme_bw(base_family = "Hei") +
geom_text(aes(label = chars, y = Freq/2),family = "Hei")+
coord_flip()+
xlab("") +
ylab("字频")
write.csv(char_by_prov, file = "char_by_prov.csv", row.names=F)
#by region
char_by_region = lapply(1:6, function(x) {
prov = subset(town_name,region==x)
chars = unlist(strsplit(prov$name_s,split = ""))
freq_prov = as.data.frame(table(chars))
freq_prov$rank = rank(-freq_prov$Freq, ties.method = "last")
freq_prov$region = x
return(freq_prov)
})
char_by_region = do.call(rbind, char_by_region)
char_by_region$region = factor(char_by_region$region)
levels(char_by_region$region) = c("华北","东北","华东","华中/华南","西南","西北")
ggplot(char_by_region %>% filter(rank<=10 ), aes(x= rank, y = Freq)) +
geom_bar(stat="identity", alpha = 0.3)+
facet_grid(region~.)+
theme_bw(base_family = "Hei") +
geom_text(aes(label = chars, y = Freq/2),family = "Hei")+
coord_flip()+
xlab("") +
ylab("字频") + ggtitle("中国县级以上行政单位字频统计(按区域划分)")
write.csv(char_by_region %>% filter(rank<=10 ), file = "freq_by_region.csv",row.names = F)
write.csv(char_by_region, file = "char_by_region.csv", row.names = F)
# draw regional map
library(ggmap)
# find each regional center
unique_region = filter(unique_prov, substr(province,2,2)==2 & region<=6)
location = lapply(unique_region$name,geocode)
location = do.call(rbind,location)
unique_region = cbind(unique_region,location)
unique_region$region = factor(unique_region$region)
levels(unique_region$region) = c("华北","东北","华东","华中/华南","西南","西北")
# top 10 char for each region
top_10_region = char_by_region %>% filter(rank<=10 )
top_10_region = top_10_region %>%
mutate(labels = paste0(chars," (",Freq,"次)"))
top_10_region = merge(top_10_region,unique_region, by ="region")
#adjust label positions
top_10_region_g = top_10_region %>%
mutate(lon_a = lon - rank %%2 *5 -3,
lat_a = lat - rank/2 - rank %%2 *(1/2)+5/2) %>%
select(c(region, rank, lon_a, lat_a, labels)) %>%
arrange(region,rank)
#manual adjustment
top_10_region_g = top_10_region_g %>% mutate(
lon_a = lon_a + (region == "华东")*(7) + (region == "西南")*(-3)
)
qmap('China',color="color", zoom = 4, maptype = "satellite", alpha = 0.8) +
geom_text(data = top_10_region_g, aes( x = lon_a, y = lat_a, label = labels),
family = "Hei",color = "white") +
geom_text(data = unique_region,aes( x = lon-6+ (region == "华东")*(7)+ (region == "西南")*(-3), y = lat+3, label = paste0(region,"地区:")),
family = "Hei",color = "white")
7 replies on “中国地名的字频统计(县级及以上)”
中国地名中还有以“地区”结尾的地名,在行政级别上它与“市”相同,在
town_name$name_s = gsub("市$|区$|县$|旗$|自治.*?$|盟$|省$","",town_name$name)
中需要做修正。
啊!多谢指正。好多类似“阿克苏地区”的...这样的话,“地”的频率应该更低才对 🙂
嗯,这个地名的话题我几年前就想写一篇短文一直没写,不过估计任何人都想不到我用地名来干了啥,改天把它码出来。
这篇我微博可是转过的...你不要说你没看到 -_-||
看过,但当时没激活脑神经,昨天夜里又想起来了。
一直苦于找不到官方的地名列表,很感谢!
🙂 官方数据需要搜索技巧,命名实在是各种乱。