(本文纯属个人观点)
最近买东西的时候,越发地怀疑现在搜寻成本是不是越来越高了。电子商务平台层出不穷,而对于自己不熟悉的领域,买东西也越来越困难。同质化的商品还好,比如洗衣粉卫生纸,这东西差别不大,随便买买用就是了。异质的商品就惨了,比如打印机,我大致只知道激光和喷墨的区别,但是具体到不同的激光打印机,我就一片茫然了。在各大论坛翻帖子,试图学习不同的术语,然后再去各家网站比较价格。或者,找个比自己懂行的朋友,直接问人家的推荐。在现代生活高度依赖工业品的今天,这种搜寻好像是无穷无尽的。今天是打印机,明天是缝纫机,后天是水龙头,大后天是吸尘机...美国网站喜欢搞限时deal,中国网站喜欢各种复杂的领劵,一头扎进去都不知道那一个性价比更高。
“杀熟”更是一个让人防不胜防而感叹世界不公的招数。比如,在美国出门租车,一大片网站看花眼,各种暗藏的收费(比如额外司机费、额外里程费、异地还车费、变更费)防不胜防。消费者往往是没法承受过高的搜寻成本的,于是对于可能没那么在意的东西,就宁愿被平台剥削了。比如我知道一些比较忙的朋友,买东西永远就是在amazon里面输入关键词,然后看都不看、直接买搜索结果第一个...
大网站靠着流量,或是巧立名目或是强取豪夺,总不能让人信服搜索第一名的就是最适合自己的。付费的简单粗暴,而免费的排名也是可以靠资金做出来的(刷单),连评价都不知道有几成水军,这日子仿佛比以前线下更难了。连费时费力的直播卖货都能搞出这么大一个产业,实在是让人惊叹这其中的高昂的搜寻成本。最近看到一个说法,互联网就是广告业。我不敢苟同,因为在我陈旧的观念中,互联网只是一个信息传递的加速器,它只不过是以前既有的交易模式的提速。不过或许网络效应超出了我以前的理解,当流量聚集在几个全国性网站、而不像以前那样线下交易有很明显的区域化特征的时候,或许搜寻成本的组成也被重新定义了。消费者被大网站绑架,新的商品很难不通过付费的形式吸引到消费者的注意力了。以前“口口相传”的口碑营销,也渐渐变成了网红的口碑,信息的集中度可能远远超出人们的想象。
营销本身也是个有规模效益的事儿。以前电视广告的时代,每年央视黄金时段的拍卖王,动不动上亿的广告费,都是人们茶余饭后的谈资。现在互联网虽然降低了营销的入门门槛——就算你只有十块钱,也可以在搜索引擎上买关键字——但却可能提高了营销有效的门槛,这十块钱可能是纯打水漂了。不说广告,只看免费的信息传播,现在还有多少人可以发现博客的内容?很多人不得不转向公众号。就算有博客,大家也是费尽心力在各个平台上宣传,然后趁着平台还允许外部链接,引流到自己的博客上。但是随着rss的日落西山,又有什么手段可以留存住这些读者呢?其实很难了。
不仅仅对于内容创作者来说很难,对于内容的搜寻者也难。最近几年明显地感觉到,利用搜索引擎搜寻出来垃圾信息的比例不断加大,甚至于找到相关的信息都要感到幸运。以前不是的,以前各种博客给予了互联网极大的多元化的信息源。而且这种信息的垃圾化不仅仅是在网络极速更新换代的中文世界。就算是英文搜索,很多时候搜出来的也都是重复而无用的,甚至有各种明显恶意碰瓷关键字的。这对于真正有用的信息的创作者来说无疑是毁灭性的打击。恶性循环,大家被逼到一个个封闭的小圈子里面去互通有无,进而造就了一个个无形的新领域的触及门槛。
那么这一波受益的是谁呢?以前经济学有传统的“品牌溢价”或者“声誉溢价”,就是说人们为了信任的品牌是愿意给一样质量的商品多付钱的。现在这种溢价依旧存在,只是可能不仅仅是品牌名声本身,而是借助各种营销渠道体现了——譬如网红主播来带个货,一模一样的辣椒酱,可能就瞬间价格翻倍。随便抓张图、看一眼过去十几年的互联网广告行业增长,动不动20%的增幅,真的只是传统广告业的转移吗?
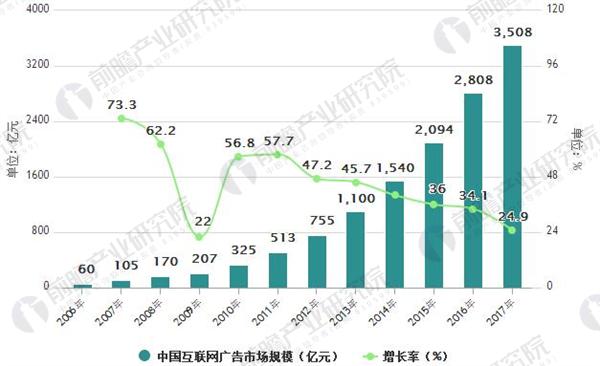
搜寻成本过高其实并不是一件好事,因为某种意义上,这是一个社会的净消耗,阻碍了资源的有效配置。有人会说,竞争市场会终究优胜劣汰,把这个成本降下来。而竞争市场靠的是众多的参与者和较低的进入门槛。一旦形成垄断,那么受益的只是垄断者。如果垄断者占据的是交易平台, 那么生产者和消费者都要为平台交税。这和给政府交税还有不同——至少后者是一个换取公共服务的明码合同,而平台的“交易税”甚至不能保证交易的公平,赢者通吃怕是没那么好看吧。
其实有个很简单的测试。在google搜索的时候,假如最上面的ads和下面的正常搜索的结果是一样的,你会不会自觉跳过付费链接而去点免费的呢?
