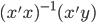今天上午纠结了好久,最后还是下决心去买了一本书。还是国内好啊,以前买书的时候从来不纠结。美国的书真心贵...
 想想这个前后纠结的过程,还是蛮有意思的,所以写写玩玩。
想想这个前后纠结的过程,还是蛮有意思的,所以写写玩玩。
1. 购买行为取决于商品带来的效用?
传统的经济学讲供求曲线,就是随着价格的上涨,需求量会增加。供给曲线我们不管,单单说需求曲线。之所以有需求曲线,是假设对每个个体来说,购买该样商品会带来一定的效用(utility)。比如最简单的食品,至少吃东西能果腹,这就是最基本的生存需求了。
每个人会对消费同一样东西有不用的(预期)效用,比如我觉得这本书给我带来的阅读价值可能有200块,所以它标价100块我也会去购买。换一个完全对机器学习不感兴趣的人,他可能觉得这本书对他的效用就是0,所以哪怕只有10块钱他也不会去买。众多个体的效用分布就组成了需求曲线(即整个群体来讲,可以接受价格与购买人数的分布图)。
如果按照上述理论,我应该没有任何犹豫的、自从我知道这本书给我带来的效用(200块)大于他的售价100块的时候,我就应该去买了。可是我为什么在剁手之前还是纠结了很久呢?
1.0 单个消费者的消费决策
纠结的原因之一可以用传统经济学来解释:我是一个消费者,而且我有着预算约束。预算约束就是说,我这个月工资只有1000块,然后我500块要付房租,然后300块要吃饭,这些都是刚性的,那么我只有200块可以自由支配来买其它东西。那么我这个月既想买书,又想买衣服,又想买首饰,又想攒钱买新的iphone、又想出门去旅游,可是我的预算约束告诉我这是不现实的。所以我为了最大化我这个月的感受,我必须从这么多项目里面选择我可以负担得起的、且带给我最大化效用和的组合。这就是传统的一个单个消费者的决策过程。
非要用数学语言的话,就是 max sum(utility_i) s.t. sum(price_i) <= budget
当然这是一个非常静态的模型:我只考虑本期,有多少预算花多少。如果我预期我下个月会突然间有一笔10000块的奖金,那么故事是不是会有所不同呢?最简单的我可以去找朋友们借钱,先把想买的都买了,然后下个月奖金到账了还款就好了对吧?这就是金融的作用了:当我有流动性约束(手里暂时就这么点钱)的时候,我还可以去“透支”未来的收入,从而达成当期的消费习惯。比较常见的就是我一下子买不起一个iphone,那么我可以去用信用卡分期支付,12期的话每期钱也就没那么多了呢。当然代价可能是我要付一定的利息....
1.1 书的效用(utility)
说起来还有一个问题。我怎么知道一本书的效用等价于多少钱呢?或者这个东西是可以简单的用钱来衡量的吗?而且书还可以去图书馆借,那么我为什么还要花钱去买呢?古话说的好,“书非借不能读也”。
我仔细想了想,对我来说,很重要的还有一点是,书买来的可以放在我的书架上...然后每次有人来找我问问题,我就可以在解释完之后、很傲娇的说,更多的细节在这本书里面呢。所以可以用来挡问题也是很重要的一点....
1.2 书的厚度与价格
很多时候我看到一本书的第一反应就是,怎么可以这么贵?然后默默的往下开始找页数。比如上面这本,看到它有1280页的时候,我就释然了,感觉好像还是合理的...这也是一种对于书的消费心理吧,虽然不是厚度决定价格,但是往往一本比较厚的书可以让人多少原谅一下卖价。可是话说回来,美国的书一本书有半本附录和文献什么也不是稀罕事儿。
1.3 书的包装与价格
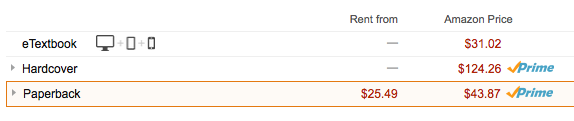
美国买书还有一点很好玩的,硬皮(hardcover)和软皮(paperback),一般同样的书两个版本的价钱还是会差不少的。这里面的逻辑据美国人民给我讲,是因为一般书刚上市的时候先出硬皮,然后可以卖比较贵的价钱,然后过段时间再开始卖软皮。基本上就是一个价格歧视了。急着看?忠诚粉丝?不好意思您多付点钱呗。比较可悲的就是这本书虽然已经是六年前的了(2009年出版),但是还是只有硬皮版本...又沉又让人多付钱,唉。
说到这里就不得不说到另一个经典的经济学模型:正版软件。正版软件的定价其实是个很有意思的事情,因为软件的复制和传输几乎是没有成本的(最多走点流量、或者很早以前就是盗版碟),所以简单的来讲就是第一份正版是肯定至少有一个人来买的,而这个人买了之后大家就可以免费拷贝了(假设盗版就是简单的复制粘贴,不存在加密解密验证什么的)。所以有人建了一个模型表示,其实正版的销售收入就是预期会买正版的人数*定价。比如我们预期定价100块会有10个人会来买正版,那和定价1000块有1个人来买正版对于厂家来说其实是一样的...反正其他人最终都会得到免费的拷贝。
当然这个现在已经不适用于这个云时代了,随处可以下载、软件免费服务收费等等的,互联网的定价模式已经完全离开这个模型了。仅仅想到了就顺便提一下。
1.4 电子书与价格
说起来图书还有一个很好玩的事儿。我每次搬家的时候都一边各种免费图书大派送、另一边咬牙切齿的说,我再也不买纸质书了。先不说违背版权的什么下载pdf这种,就说出版社授权的电子书、比如kindle上面的,我每次买的时候还是会多多少少的纠结一下。比如我今天买的这本书,有kindle版但是也没便宜特别多(一半是8-9折的样子),所以我想了想加上可以摆在书架上面炫耀这种因素作祟,最后还是去买了纸质版。我好像常买的kindle版就是那种小说什么,读完了一遍肯定就再也不会拿出来翻翻了,也不想搬家占地方(基本就是那种只要搬家就开始送人的书)。所以到现在我买书给自己的底线就是,这本书搬家的时候你确定要一起搬走么?确定的话那就买呗...
国内倒是很多电子书单位定价真的很低,有点像jobs当年把一张cd拆成单曲出来卖的意思。这里的定价学问就更多了...所以说定价是经济学永远的话题呀。
话说我的kindle也已经开始埋灰了....唉。
1.5 同伴效应与价格
同伴效应(peer effect)说起来也是很好玩的一个消费者心理。上面我们一直在说一个孤孤单单的消费者,他总在自己跟自己纠结。同伴效应就是说,本来其实我也没有特别想要某本书,但是架不住周围总是有人提到这本书如何如何好,别人买到了之后经常拿出来引经据典什么的。久而久之我就开始俗称“长草”,然后总会有要么忘了要么“拔草”的一天。所以说女人败家之处还在于,你不是一个人在消费!你是一群人在消费!
这本书也是长草了有段时日了,经常说到什么的是我就心里在想,如果这本书在这里就好了,我就可以直接把书拿出来说服你们了。来来回回几次,我想买过来的心情就越来越急切——直到下单的刹那开始释放焦虑。
1.6 预期效用与定价
说来还有个很好玩的事情。我买这本书的时候,一看到价格是差不多100块,我的第一反应居然是“这么贵,那肯定值得买”。这多少有点像奢侈品——买的时候稍微肉痛一下,然后才觉得买吧买吧。也就是说消费本身不是一个纯粹的效用和成本的问题,而是这个过程本身也是一种享受。譬如小时候,如果谁过年攒了好久的压岁钱零花钱什么买了一个游戏机,那不知道要羡煞多少周围的小朋友。所以买东西的时候那种“颤抖”与纠结的心情,本身也是要计入消费行为带来的效用的。类似的例子如拍卖,拍卖本身斗志斗勇也是挺好玩的一件事儿,很多人往往在这个过程中会因为“赢家”带来的满足感而愿意多付出一点钱呢。我在想这本书如果只买20块,我估计毫不犹豫的就像买各种日用品一样“一键下单”了,反而少了各种乐趣和拆包裹时候的满足感。(所以说女人是有一种天然的受虐心理么?)(更多)
1.7 书的价格与运费
在国内的时候,我区别自己对一个东西的耐心与否,一般就是看我从哪里买:如果我特别急着要,一半是找一个可以提供当日或者次日送达的b2c网站买、甚至自己跑到实体店里去找;如果不是很急着要,那么我就慢慢的在网上淘,然后也不在意买家所在地(一般江浙沪还是比较快的),反正慢慢的能寄到了就好了。
到了美国还是如此。因为这本书比较贵,反而在选“运输”的时候我选择了“两日免费送达”,一般不急用的便宜的日用品我都是选择“慢慢送吧、记得额外送我一块钱”。所以说已经付出了那么多纠结了之后,在下单之后选“运输”的那一刹那我反而是更没有耐心了。
但是我又想了想,如果亚马逊问我,“多付1块钱次日送达”和“免费1周送达”,我估计我可能还是会选免费的选项...此时心里嘀咕的大概是“我已经付了这么多钱了你凭什么还要我付钱?” 然后一边选了免费送达一边气鼓鼓的关掉网页。所以也有研究说明,“Customers love free shipping too much so they even 'pay' for it"。人们的心里永远是,从我这里拿走是是很难的!(英文的意思就是,一家免费送货的东西 可能比 另一家商品价格+运费 还要贵,但是人们就是喜欢免费送货所以宁愿多付钱买第一家的,来源)。

2. 耐心与非耐心 (贴现效用)
其实上面反复提到的一点就是“耐心”。说起来“耐心”是经济学理论里面很好玩的一个东西,不仅仅是在微观的消费理论、宏观模型里面也会有动态规划(有限期、无限期)那些,也是要对每一期的效用贴现什么。直觉上来说,就是谁也不知道未来会发生什么,所以拿到手为准,俗称“活在当下”。
这里的表现比如,我花钱越多就希望越快拿到越好,虽然我明明知道明天我可能就没有这么在乎这个东西了——下一次的幸福的感觉要等到包裹送到的星期五...这算冲动型消费吗?
3. 消费与啰嗦
话说回来,我之所以会在这里这么啰啰嗦嗦的写这些东西,其实只是因为一早花掉了100块钱去买那本书。然后各种心如血注,需要唠唠叨叨的发泄一下。但是又不能太明显,所以就跑到这里打字写blog来了,还要拿出那么一堆看似相关的经济学理论只是为了说明“我不是在乱花钱哦,我还是一个理性的消费者,我的一切行为都是理智上说的通的”。哈哈哈哈。说白了,女人就是爱给自己找理由 T_T
------------------------
大家看着玩就好,不要当真....