所以各个学科之间就是这么相互交叉的么?...
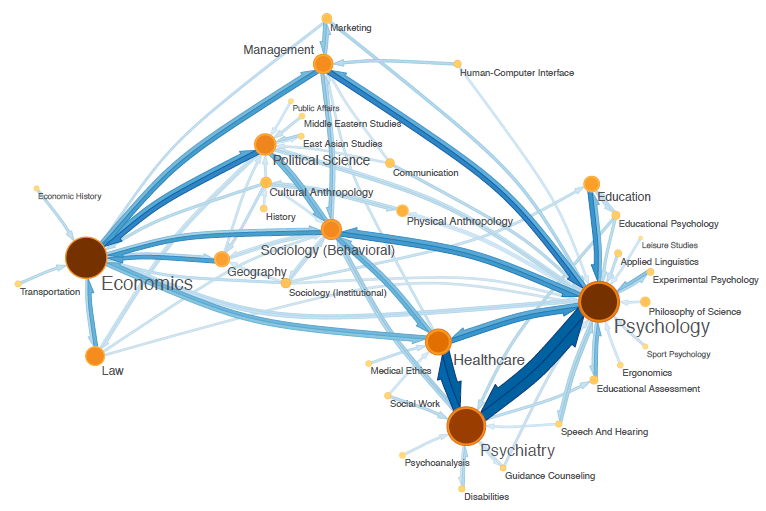
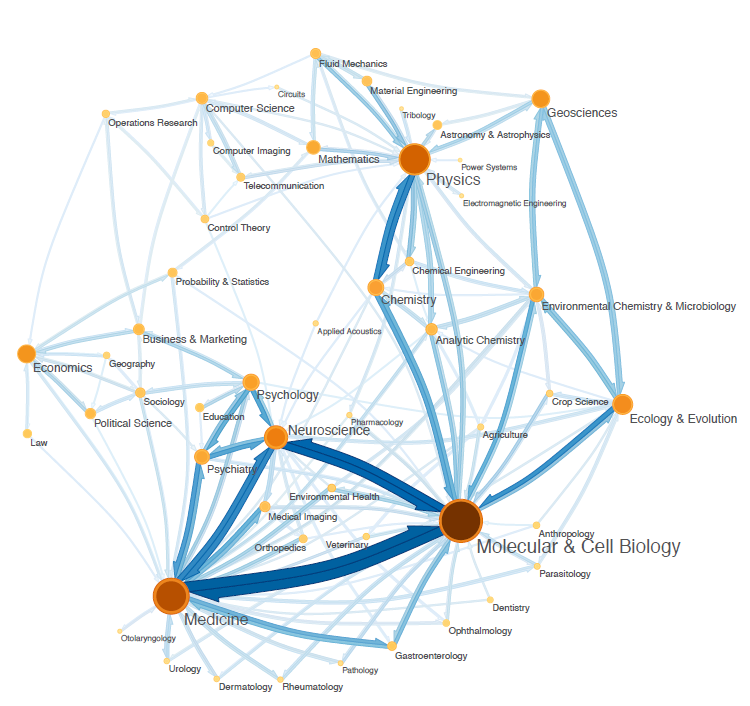
所以各个学科之间就是这么相互交叉的么?...
最近一直在看Community Discovery这一块儿的论文,深深的感觉现在就是一个矿工,不断的想方设法挖出来更有价值的信息。而且不是一个点一个点的突破,而是需要寻找出一种脉络,串联起所有的信息来。头痛。
最近的情况是,有一个well-connected的网络,然后我想把它稀疏化、打散成一个个独立的community的感觉。这样就可以分别识别每个community的特征什么的。所以厚着脸皮找施老师讨了几篇papers。而主要的问题是,数据太大了...11M nodes, 20 M edges,还是directed weighted network...我直接放弃了把这些数据从SQL Based data source中挪出来的想法,还是先努力的减少一些edges吧。
先罗列几个相关的术语:community discovery, graph partitioning, network clustering, network sparsification, modularity。了解一个领域最好的方法大概就是去读literature review了,所以乖乖的要了一篇:
Srinivasan Parthasarathy, Yiye Ruan and Venu Satuluri. "Community Discovery in Social Networks: Applications, Methods and Emerging Trends", in Social Network Data Analytics 2011. (NS, DM)
最契合我的想法的就是cut类方法——remove some edges to disconnect the network, then (drop isolated nodes with degree = 1 (could be added back later as auxiliaries to each community)。
那么就先从这一类方法开始说。比较经典的算法呢,是希望砍掉一条边以后,community内部的凝聚力不变,外部连接变差。基本上常用的就是Ncut(normalized)和Conductance、KL object、Modularity这些指标。比如KL算法,就是从二分图开始,不断迭代的去寻找如果交换某两个点所属community就可以减少edge cut的边。可惜的是,这些最优化问题都是NP-hard....随着数据的增大算起来会异常吃力。KL算法本身迭代也是相当考验计算能力的(贪心搜寻)。
然后就是凝聚(或者切分)类算法。凝聚就是先各自为家,然后附近的相互结合在一起,直到理想数量的社群结成;切分则是先从一个整体开始,然后每一步都切成两份这样。这些都算是层次聚类,最后可以给出一个长得像二分树的系统树图。这一类算法有Girvan和Newman切分法:每一步先计算每条边的betweeness score,然后把得分最高的边砍掉,然后再重复这个步骤。嗯,问题依旧是这样的迭代很耗时间。
频谱类算法(spectral algorithms)。听这个名字一股经典风就袭面而来。基本上这类方法就是仰仗特征向量(eigenvector),比如adjacency matrix的特征向量,然后top k特征向量就定义出来一个k维的特征空间,然后就可以用传统的比如k-means这样的方法来聚类了。说白了就是降维、降维。可惜这种方法依然算起来很消耗资源,光算那个特征向量就是O(kM(m))的复杂度...基本在大矩阵下就投降了。一个概率的方法就是Graclus算法,基本的直觉就是基于加权的normal cut measures再做加权核k-means便可以给出基于特征向量聚类一样的结果,而计算消耗相对少一些。
多层次图分割(Multi-level graph partitioning)。这个就是相比而言快速有效的方法了。基本的想法就是,先压缩原始图像到一个小的图像、分割这个图,然后再映射回原来的图。毕竟小图分割起来就要快的多嘛。这类的方法除了上面说到的Graclus,还有Metis(以KL object作为measurement),以及MLR-MCL。
马尔可夫聚类(Markov Clustering,MCL)。基本的想法就是,两点之间的信息传递是随机流(stochastic flow)。MCL对随机矩阵会做两个操作,扩张(expand)和膨胀(inflate)。前者就是简单的矩阵平方,后者则是用一个膨胀参数(非线性)来撑大彼此之间的差距,最后再重新normalize。这两个步骤交替进行。这样的话,原本community中紧密相连=的两个点则会更紧密的相连,而不同cluster之间的连接则被弱化。这样最后每个community之内的点都会流向某个attractor(吸引点),从而我们可以识别各个cluster。感觉这里有点收敛到一些不动点的意思。MCL的弱点也是计算消耗。矩阵乘法在开始边的权重没有弱化的时候是非常消耗时间的,此外MCL倾向于产生不平衡的群落,尤其是可能产生一堆很小的群落或者一个很大的群落。
MCL的改良主要是在引入惩罚项(regularized MCL)和加入多层次(multi-level regularized MCL),以减少不平衡的clusters和解决MCL难以scalable的问题。后者也简称为MLR-MCL,就是刚才多层次分割里面有提到的那个。
局部聚类(local graph clustering)。局部方法基本上就是从一个给定的顶点(seed)出发,寻找符合条件的群落,而并不关心整个graph的情形(除非所有的群落需要覆盖全图)。计算上就是利用随机游走(random walk),从一个群落的内部开始,一点点的向外扩张(有没有很像page rank的感觉?)。最早的Spielman and Teng就是这样的基于顶点随机游走的算法。后面Andersen and Lang改进了这类方法,可以从一堆seed sets出发而不是单单一个顶点。此外,Andersen还试图在随机游走之上加入re-start(即个性化的pagerank)。
再需要提及的就是在动态网络(dynamic network)之上的community discovery——不同于静态网络,动态网络是本身一直在变化的,正如我们一直在用的facebook、twitter这般。还有异质网络(heterogeneous network)和有向网络(directed network)。呃,这部分我就没细看了,貌似蛮复杂的样子...就是其中有一个Community-User-Topic(CUT)model看起来蛮有意思的,准备明天去找这篇paper读一下:
D. Zhou, E. Manavoglu, J. Li, C.L. Giles, and H. Zha. Probabilistic models for discovering e-communities. In WWW ’06: Proceedings of the 15th international conference onWorldWideWeb, page 182. ACM, 2006.
嗯,到总结了~前面一直在说的就是计算、计算、计算。
好了,到此为止~继续看其他paper去了。
只是罗列一些这一两年比较关注的具体领域。
总而言之,我觉得我越来越不像一个学经济学的孩子...可怜。好吧,这些最多算是紧跟潮流吧,很多东西回头看看也没觉得多有意思。
被一份工作逼到如此程度也算是奇葩了...哎。最近的感觉就是,我还是去关注一下business side的一些趋势吧,多看一些new business models,毕竟这才是真正创造出来价值的。
大概有一个多月,一直在酝酿这么一篇文章。有很多的东西想说,却每每到口边欲言又止。总归沉淀的久了,该说还是要说说吧。
1. 关于大数据
我是莫名其妙的就被拽入这个领域的。虽然我也经常在一些不得不包装的场合不停的用到“大数据”这个词,但说到底我还是觉得它是硬生生的被炒作出来的。从2011年到现在,有幸在国内国外开了无数的跟“大数据”有关会议,有小有大,有偏学界有偏业界,可是越开越麻木。以至于到最后,我关心的问题就成为了几个:
曾经有人戏谑般的问我,“你一个做分析的关心这些high level的东西干啥?”,我的回答很直白,“为了保证不让自己失业”。当然这话有五分打发之意,归根到底的原因可能是,我在寻找灵感,在试图最大化分析的价值,在别人的失败中学习经验(输家往往比赢家更有意思)。换言之,我没打算一直做分析。自从在eBay深度接触了某些做事极端细致的同事之后,我觉得这个领域做到极致也怕就是如斯了。拼不过。
有些问题越来越不关心,因为从分工的角度来看绝非我的比较优势。比如,XX架构改善了数据库存储、查询;XX模型经过某些改进获得了几个点的提升;XX产品可以支撑更大量的数据和更好的实时并发性(这些东西对我来说,有就用,没有也不强求);XX平台实现了XX算法(没有成熟的接口我是不会去碰的)。可能对于数据分析模型的理解(此处单指统计或者机器学习模型),我已经过了那个狂热的沉浸于美好的证明或算法无法自拔的阶段。从一个更高的角度来看,基础设施尚未建设完成(更广泛的数据源搜集、聚合,以及强有力的分析平台建立),谈那么多奇技淫巧有什么用?每每看到BI这个词,就想吐酸水...平心而论,eBay的基础设施建的还是比较好的,一个数据仓库就有几百人的技术团队在维持。
总结一句话:路漫漫其修远兮,做的好的就那么一两家。单单靠分析赚钱没那么容易,先把人才的缺口补上吧。
2. 关于分工和角色
说分工之前,先说说现在的工作。在eBay,听起来很曼妙的两个音节,却很不幸的在它的海外研发中心。若我是个工程师研发产品也就罢了,可惜还在分析这种需要跟业务部门频繁交流的岗位。当然做什么事情都有好和不好的一面,没有绝对的。只是当你还可以选择的时候,当你处在一个不同的职业发展阶段的时候,会有不同的诉求。
回头看,如果我知道现在的工作是这样的模式,我还会在一开始如此选择吗?会的,我很无奈,但没有更好的选择(当时下决心一定要去一个英文环境)。“不畏浮云遮望眼,只缘身在最高层”。那个时候位置太低、浮云太多,很多事情看不清楚。我觉得我很幸运,毕业之后的两份工作都没有让我后悔过。
eBay对我的最大改变就是,让我重新拾回了很多技术细节。比如,对于分布式的理解越来越深,parallel SQL 越写越熟,R的某些包越用越顺手,Shell和SAS被重新拾起,诸如此类吧。这也是我当时离开咨询的目的——做pre-sale support、跟客户天天腻在一起,没有脚踏实地的感觉,每天脑袋瓜子里想的都是“客户到底是怎么想的”,每天都在做各种各样的利益分析。时间久了,觉得每天都在跟演戏一般。
可是在分工链上,技术绝非我最擅长的。开什么玩笑,一个直到研究生都没怎么受过正规编程训练的人,怎么可能拼得过那些国内顶尖学校CS或者EE出身的、一直专注于此的精英们?就算勉强加上模型这块儿,就算凭着还算可以的数学基础我事后补修了很多门机器学习和统计学的课,我也不觉得我能胜得过那些一早儿统计和计算机兼修的有志之士们。太多东西不是纯粹智商和努力可以弥补的,时间是不可逾越的鸿沟。当然如果下定决心一直做下去,也未必没有成就——可是要我抛弃心头挚爱的经济学,做与之完全无关的事情,我做不到。
有个很好玩的词儿叫做“street sense”,我也不知道怎么翻译为佳。有点类似于soft skill的感觉。在我的同事中也有少数这方面很强的人,能明显看到他们的成就卓然不同。对我来讲,这样的感觉或许更佳吧。
3. 关于积累
工作久了,很多人就会跟你说“工作经验比学历更重要”。我的感觉是,看哪个是短板吧?两个还是均衡发展比较好。要不在labor economics之中,也就不必把experience和years of study都作为回归变量了。
工作经验是个很神奇的东西。一方面他会加快你做特定事情的效率(指数式),一方面他也会束缚你的思维。周围看到了许多从技术转到管理岗一开始很不适应的案例。思维方式完全不同嘛。
我个人喜欢把工作经验分为两部分:广泛适用的经验和内部适用的经验。在一个企业一个部门,其实积累的更多更快的是更适用于本部门的一些经验,这两种经验发展不均衡在那些一毕业立刻进入一个企业、一直没有离开过的人身上尤甚。实话讲,如果想在一个大企业里面很快的发展,内部经验尤为重要。Fit the culture。而广泛适用的经验其实对于适应更多的环境、岗位更重要。把赌注都压在一个篮子里面是不明智的...
4. 关于野心
我一直觉得我是一个不安分且具有野心的人。不过时间会把人的奋斗精神消磨,尤其是在一个很容易就活的比较舒服的环境中。
可是当太多事情不能控制,一切浮华便如过眼烟云,与己无关。
这期AER里面的一篇paper看起来蛮有意思的——
Word-of-Mouth Communication and Percolation in Social Networks, by Arthur Campbell
整篇文章非常technical,纯纯的theoretical research。不过有些直觉和结论蛮有意思的。我就试着小小的讲解一下直觉。
设想这么一个情景:有一家厂商试图向一群人推销一样商品,幸运的是他知道这个网络的结构,所以作为新媒体营销的一次尝试,他决定暂时不采取大范围投放广告的方式,只接触部分人然后依靠大家的口口相传进行产品营销。只有获得该消息的消费者才可以购买商品。对应现实中类似的情况,就是大家在微信上投广告,然后只能借助朋友之间的相互转发或者群内转发来影响其他用户。
在这样的情况下,作者证明,借助口口相传的情形相比于直接全面投放广告而言,消费者的需求更有弹性。这样的结果就是,这个厂商的定价会相应的变低,以吸引更多的消费者来攫取利润。
群聚效应:再复杂一点的情况就是,人们对于一件商品的价值估计可能和周围朋友的数量有关。比如周围朋友很多的时候,人们对于一件漂亮衣服的估值就可能更高(炫耀嘛),而一款集体游戏的价值可能也展现的更充分。出于这样的考虑,在一小群人中,便会出现需求曲线的弹性远远低于全面投放,从而厂商得以制定一个更高的价格。如果一群人是因为兴趣相投偏好相似而聚在一起(物以类聚),那么这种需求的刚性可能会更为明显。
分散的群落:再想一想网络的结构。如果这个网络是相对而言较为割裂的(人群与人群直接交流不多),那么由于信息传播的不充分,整体的需求曲线会变得更加有弹性,整体需求也会下降,导致此时厂商不得不降价来实现利润最大化。这可能和直觉上大家觉得既然人群之间信息传播不充分,便可以实现群落之间的价格歧视——事实上,可能人们对于商品的价值估计受这样的网络割裂影响更大,所以大家多少会有一点观望心态。
广告投放策略:在有口碑效应存在的情况下,口碑效应和直接广告投放会成为“策略互助” (strategic complements)——即他们彼此之间会相互加强。因此最优策略可能是,如果厂商希望低价买更多的人,那么他们应该将广告定向投放给那些相对而言较为边缘和孤立的人群,以期克服网络中信息传播的障碍,实现利润最大化。这和我们传统的借助网络营销中一味的去找"大V"转发的策略相悖而驰。如果厂商只希望一小群人以高价购买,那么他们应该投放广告给那些热门用户。所以,取决于具体的商品和厂商的战略布局,借助社交网络营销可能应使用不同的策略。
---------------------------
最后的废话:这篇paper居然是发在AER而不是Marketing Science上,多少有一些风向变化的感觉。看看最后这样的冲击会积累到多大吧!