前几天看到最新一期的 American Economic Journal: Microeconomics 出来了,扫了一眼目录然后发现有两篇papers挺好玩的。也可能是现在人在电商的缘故,对online marketing格外的敏感,所以先拎出来一篇对比在线个购物和传统购物中新品牌探索的论文,一睹为快,顺便忍不住和大家分享一下:
Pozzi, Andrea. Shopping Cost and Brand Exploration in Online Grocery, American Economic Journal: Microeconomics,4(3), p96-120, 2012
AEJ版的米有权限下不到(有权限的童鞋帮忙给我发一份),去作者网站上找到了working paper版。有兴趣的不妨去下个PDF看看原文,虽然有点小长(econ的论文难得见到50页以下的-_-||,命苦啊)。
---------一点经济学理论背景知识----------
相关信息提供结束,下面开始全力关注正文。网购出现之后,由于其一堆让人欣喜的特性,受到广大人民群众的广泛欢迎。作为一个从高中时代就开始支持电商的孩纸,我个人网购的主要理由如下:
- 便宜:相比于实体店,网店房租等固定成本投入低的多,所以价格上自然有所让利。加之现在电商之间竞争惨烈,消费者自然可以期望一个更接近于博弈均衡价格的价格(基本就是,会稳定的趋近于成本)。优胜劣汰的信息丰富下的完全竞争市场模型嘛。
- 选择丰富:实体店往往受限于店面面积,能陈列的就那么几个牌子。而网购则不同,可以一下子把更多的东西都放在上面,任君挑选。有的时候可以很方便的买到一些平时便利店买不到的小东西,各种造福生活。当然还有各种限定版或者水货之类的?
- 便于比较:比较一方面是价格,另一方面还有商品的评价。比如买电器,在国美苏宁基本上就是推销员口若兰花,根本不知道一件东西到底有什么缺点(比如西门子关不上冰箱门)...而在电商网站,可以很容易的看到其他购买者对于商品的评价,各种实拍图什么的,有利于作出更理论性的购买判断。再者,选定了款式之后,价格比较也是很容易的。呃,作为一个有经验的网购者,基本上不会出现严重的被欺骗交易——网购市场一分钱一分货的道理还是一直存在的,所以我很少会买特别廉价的东西,还是习惯于一个reasonable的折扣(相较于实体店)。
我曾经很关注网购市场,尤其关注的是其中的交易机制设计。这个名词听起来挺专业的感觉,其实不过是一些很细微的规则:比如,淘宝商家商品上架要不要收费?商家要做哪些身份验证?商家的声誉是怎么积累的?商品打分评价是怎么计算的(豆瓣现在对电影图书等评分系统有了更好的算法调整,避免过高/过低的个别评价干扰整体结果)?退货换货制度是怎么设计的?保险又是怎么规定的?
这些看起来细微的东西,累积起来,就在一定的时间范围内决定了一个市场的生态状况。简单的说,每一次淘宝对于收费等等的调整都会引起很多商家的地震,优胜劣汰本来无可厚非,只是这其中牺牲的卖家有的时候还真让人感觉制定规则之人的凶残~ 嗯,淘宝需要经济学家,嘻嘻。这些东西真的不是拍拍脑袋想出来就可以的嘛~
而在一个给定的制度下,从更微观的角度,我们不仅仅可以看到商家之间的竞争,更多的也可以看到消费者行为的变化。比如现在更习惯淘宝商城或者京东这些B2C平台的购物者,和那些喜欢在淘宝C2C中浏览购买的人群(或者同样的人购买的商品),往往都是呈现一定程度的差异性的。简而言之,这是对于消费者的一个自然划分过程,通过他们对于机制的选择体现了他们本身的属性:购买力,价格敏感度,风险偏好,时间成本,计算机使用程度,决策理性程度等等。这些属性共同的,在网购的市场中,决定了消费者购买的产品和购买地。在这些特性之中,风险偏好貌似是网购市场中最最让人关注的事情——可能是因为,市场机制的调整会直接的影响不同风险偏好程度消费者的购买行为变化。一般说来,感觉习惯于B2C的消费者会有更高的风险厌恶特性——哪怕付出稍稍高的价钱。为什么这里我说B2C价格一般会高一些呢,主要是B2C为了进入市场(比如拿到淘宝商城的执照),需要一次性或者长期的付出更高的成本(进入成本或者声誉成本,或者像京东商城那样趁着奥运会打广告什么的)。短期之内低价可能是驱逐其他竞争者的策略,但长期看来这些成本必然还是由消费者买单的。
风险偏好的一大体现就是,消费者对于既有商家或者既有商品品牌的认可。比如,对于一些日常用品,我会倾向性的选择某些品牌。相机,嗯,Nikon或者Sony吧;笔记本自然是IBM(好吧现在是联想)的Thinkpad;出门一般不会去坐小航空公司的航班,碰到天气不好先取消的肯定是这些,还是大航空公司的调度能力强一些。之类之类的吧,人们对于品牌的依赖无处不在。品牌理论有很多,我有些武断和路径依赖的认为,品牌存在的核心价值就是降低了消费者的选择成本——习惯性的去购买自己习惯的商品,不会出现什么突发的不适应情况(当然也就没有了意外惊喜)。当然,品牌还有一个功能就是向自己周围的人传递一些信号,比如投行的孩子们一般需要一身名牌来武装自己,而IT男则常年拎着各种小众神器招摇过市吸引MM眼光...奢侈品基本就是这个目的的。然而,无论是哪个目的,品牌的塑造总是有成本的。一遍呢,是口碑长期的积累,类似于“百年老店”这样的声誉,这个是时间赋予的;另一方面,则是广告投入。最近看奥运会的童鞋有米有发现,比赛之间穿插着各种广告,不断的用某些名词来刺激人们脑子中对于品牌的反应和认知(恶心的例子如某年春晚,恒源祥的“羊羊羊”,导致大家的电视机集体呈现死机状~你懂得)。
就算我们耳熟能详的一些品牌,也有子品牌和多品牌策略,可以方便的区分不同的顾客群。典型如各大酒店连锁集团,例如喜来登,高端的有以私人管家服务著称的“瑞吉”(补一句,拉萨有一家,让人各种流口水啊~);商务客有艾美、威斯汀和喜来登;然后还有稍稍平民的福朋喜来登。日常生活中,你知道的,什么潘婷啊、沙宣啊、飘柔啊都是宝洁的,对吧?这个世界大概只有强大如apple,才能上下通吃吧...一个iphone搞定所有孩子。微博最近流传了一张很经典的快消品品牌图:the illusion of choice,嗯,其实这些都是一家的...
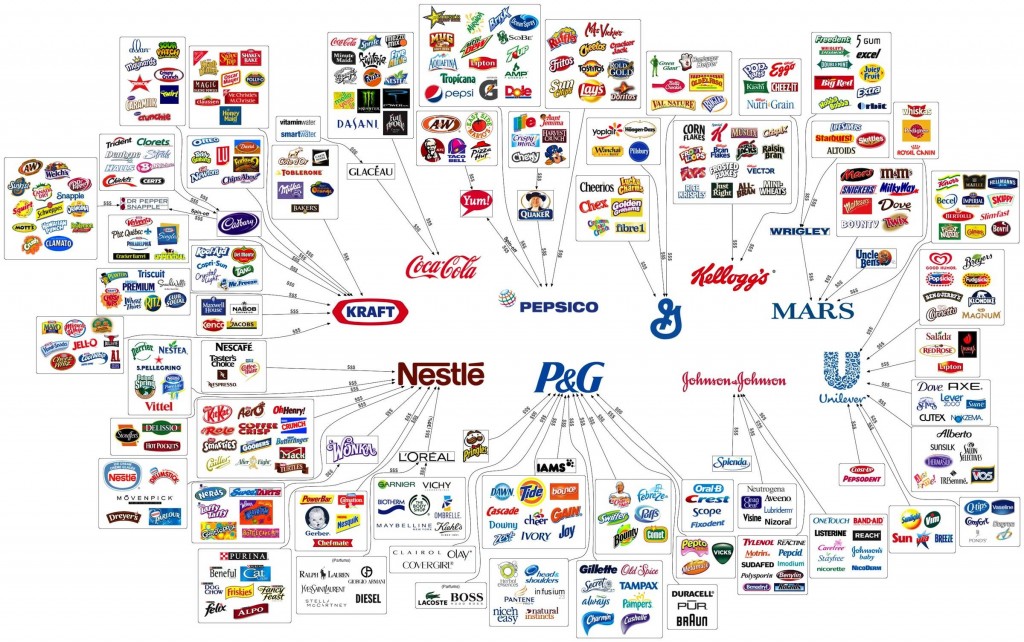
那么一个关键的问题也就浮出水面了——在网购中,人们对于新品牌是什么态度呢?我们一边看到淘宝让很多江浙地区的中小企业有了打造自己品牌的机会(比如裂帛?),另外一个方面网购的时候出于风险厌恶和时间紧迫,可能人们更多就是匆匆买完自己需要的东西而已。那么,是不是对于人们在传统超市里面买的更多的快消品,网购市场会使得新品牌更难出头呢?而对于一些实体店更难买到的东西,或者人们更追求风格和设计的商品(比如女装),网购中反而新品牌更容易确立呢?
----------实证结果-------
罗嗦了这么多,终于回归这篇论文,让我们来看一下实证的结果吧!
先说数据集,嗯嗯,这个永远是我们首要关心的。当然,世界上永远不可能有那么完美的数据,可以100%科学的回答这个问题。不过有的时候选择性样本也不是什么大问题,如果这个样本代表性还是可以的话。在Andrea这篇论文中,她的数据来源于美国一家拥有1500多家门店的连锁超市。有意思的是,这家超市一是有会员制度,二是它同时提供网上购物。也就是说,你如果是这家店的会员,既可以自己开车去超级宽广的超市购物,也可是坐在家里点点鼠标等人送货上门。具体到数据,作者拿到了11640个家庭2004到2006年之间的购物样本(时间有点早呃),这些家庭同时有实体店和网络商店的购物记录。数据是scanner level的,就是可以看到购物清单,包含商品名称价格等等。
然后,作者为了保持一个比较好的可比性,选择了grocery这个类别,基本就是我们常见的各种快消品:食品、日用品这些吧,可以参见上面那张图。作者对于新品牌的定义可能和我们感知的有点不同:对于每个消费者来说,买他以前没有买过的品牌就算一次新品牌探索行为。不管这个新品牌是不是真的新上市的。特别的,作者格外关注cereal的购买(燕麦片?),体现了人们对于早餐的选择。
好了,基本的数据情况就是这样,我们先来看一眼简要的结果:网购中,消费者购买新品牌的倾向比实体店中低13%。
可能的原因是:
- 网购快消品更多的是为了节省时间
- 消费者对触碰不到的东西质量更为忧虑
- 购物网站上更多的呈现“历史购买记录”等对新品牌购买有负面影响的信息
前两点有点显而易见,最后一点则是非常有趣的。去年接触了很多推荐算法方面的东西,从理论的角度来说,很多现行的推荐算法确实倾向于推荐热门的商品。最简单的,如amazon初期使用的,购买过XX的人还购买过YY,这样一来越来越多的人可能会被导向YY。一些新品牌因为可能比较小众,就比较难以在这种推荐算法中脱颖而出。如果是电影还好,至少还有导演演员等等可以做一些基于内容的推荐。但是,对于快消品来说,本来品牌的竞争就已经呈现白热化了,推荐算法除非特别调整,否则还是很难把这些近乎“冷启动”的品牌推荐出来的。此外,推荐算法的diversity一直是一个评价算法很重要的指标,虽然很多简单的算法带来了较多的转化率,但是这样长此以往会出现热门商品更热门,冷僻商品更冷僻的两极分化。热门商品由于各个电商之间竞争激烈,很难获得高额利润,这样下来不一定电商的利润会更高。
与之相对的,是实体超市中的“推荐算法”——强大的人肉推销员。在实体超市中,会有各种试吃试用的机会,还有推销员现场演示,这样的使用体验感知会抵消人们对于新品牌的质量忧虑,反而有了猎奇的好奇心。这样一来,冷启动也不是一个冷冰冰的问题了。
嗯,接下来我们自然关心的是,一个消费者在什么情况下,会从传统超市购物转向网络购物呢?这大概是很多电商极为关注的问题。对于这个问题,Andrea使用了一个简单的线性模型,考虑了距离、运费、是否为周末这几个因素,外加一堆控制变量,主要是受教育程度、收入等等家庭特征因素。然后对于燕麦片的需求,主要考虑了价格、以前是否购买过、购买渠道等等因素。
嗯嗯,最后高潮来了——估计的时候,Andrea使用了贝叶斯估计(Gibbs随机抽样),对于购物渠道选择估计结果如下:
- 运费越高,网购可能性越小。
- 越有钱的人,越倾向网购(当然财富本身可能是内生的,由教育程度等等决定)。
- 周末的时候,人们更可能出门购物而不是网购(注:这个结果可能更适用于美国)。
- 住的离超市越远,越倾向网购。
- 18-35岁的人群更爱网购。
而后,对于消费者品牌选择的估计结果为:
- 网站界面设计的影响:新品牌在网购中如果希望脱颖而出,往往需要提供一个特别诱人的巨大折扣(4$以下折扣基本无作用——而一般一盒麦片也就是三五刀而已)。
- 周末的时候,新品牌看起来更容易被发现。
- 网购中,人们对于质量的忧虑更高。
- 人们时间不足的时候,购买新品牌的可能性降低。
那么,网站上的推荐列表影响到底有多大呢?作者实施了一个simulation,从“历史购买记录”到“相似购买推荐”,实验结果是两年的时间内预期可以提高23%的新品牌探索比例,但是依旧低于实体店。同时,模拟结果也侧面证实了,一个新品牌进入网购市场的时候,不仅仅面对实体店中存在的进入壁垒,同时还受到人们历史购物习惯和推荐列表的双重影响(尤其是历史购买记录,成为了一个新的无形的进入壁垒)。
那么,最后的指导就是,新品牌若想在网购中谋得一席之地,类似于病毒营销的强力广告营销是不可或缺的;与此同时,如果网站的推荐算法包容新品牌,那么新品牌将受益,更容易脱颖而出。嗯,满符合直觉的嘛~ 在一个成熟的市场要脱颖而出,不靠创意和广告怎么可能呢?此外网站算法导致的信息不同流向,自然会很大程度影响网购的品牌选择——不像实体店,网络中的信息更多的呈现“被设计”感呢。