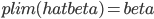在上一篇[cref %e7%a4%be%e4%bc%9a%e5%ae%9e%e9%aa%8c%e7%9a%84%e7%89%b9%e6%ae%8a%e6%80%a7%ef%bc%88%e4%ba%8c%ef%bc%89]里面回顾了费歇尔的实验设计三原则之后,那么归根结底,我们为什么要做实验?
从一个纯经济学的角度来看,社会实验的目的之一就是在我们面对现有的数据受到各种局限、从而无法完美的回答我们关心的问题的时候(说到底还是各种内生性问题),采取的一种主动出击寻求答案的方式。故而,实验之前我们一般是有一个基本的思路和方向的,然后更多的想去看一下这个东西到底是不是在现实中就是这个样子。从这个角度而言,社会实验是在很明确的我们知道想得到什么信息的方向上去设计的。
说一下从我个人的感觉上的最大的在业界和在学术界的不同,可能就是data上。在学术界,难得会有非常好的data,所以很多的时候我们都是在有限的数据资源的基础上、去力求用最完美的方法估计我们感兴趣的值。数据源有限的原因有些是历史上的,比如我们研究几十年前的事情,自然当时没有电脑等东西可以完善的记录所有的事情;有些是数据本身的性质决定的,比如宏观里面常用的gdp等东西,中国的数据是1978年之后才有的,而且一般都是年度数据,更受限于国民统计汇总的层级汇报,自然会有一些测量偏差;有些是业界有数据,但是没法得到,这里就牵扯到一些隐私等法律权益、或者数据接口API等开放的幅度的问题;还有些是知道数据在哪里、也可以得到,但是成本太高,比如个人层面的数据,除了全民普查外很难有全覆盖的数据,一般只是小规模样本;最后的就是信息并不是直接以数字的方式记录的,比如twitter上面的用户微博记录,因此需要借助文本挖掘等手段进一步深究。
业界主要提供的就是第三类,大量的个人用户的数据,比如淘宝上各种买卖双方交易的数据。现在淘宝的交易量真的是非常大,而且每笔交易都是真实的现金往来的(我们不考虑非法的洗钱状况),其实背后对应的就是一个真实的微观交易的集合。但是这个交易数据怎么用?最简单的,我们可以看价格,对于同质品之间竞争已然白热化的,已然相差无几,那么价格几乎就等同于scanner price,可以用来衡量物价的波动。当然,网络交易有不同于实体交易的地方,比如受限于运输成本和采购的规模效应,肯定会和超市里的价格有所区别。另一方面,网络上的价格信息流动非常充分,越来越接近于理想中的完全竞争市场对于信息的要求,所以多少也让人兴奋。
另外一个有趣的数据可能就是微博,因为其实质上是一种“短平快”的信息传播渠道,会把信息通过简单的几个信息源极快的扩散到整个网络中去(所谓的influencer model)。所以现在很多人炒得很热的微博营销也是背后有着深刻的渊源的。但是同样的,信息传输成本降低的背后就是噪音的增加,因此对于微博的信息分析起来除了文本挖掘技术实现之外,就是怎么去在大量的噪音数据中寻找到有用的信息。从这个角度而言,就是在进行任何文本挖掘或者信息提取之前,是不是有一个主导的思路去明确的知道需要挖掘的信息。业界很多时候不是数据太少了,而是太多了,以至于大家根本不知道这些数据可以怎么用,所以data mining成为了救命稻草,一窝蜂的上去看看能不能挖到金矿。从我的角度看,每一个data mining算法背后必然是有一种主导的思想来支撑的,比如决策树,不过是分类统计最优化路径的感觉,这样的直觉还是蛮强的。所有数据分析的任务无外乎两个字:降维,怎么在一个多维的好烦的数据海中找到自己最感兴趣的数据,可能是几个变量之间的关系,可能是一个综合指标的创建。最简单的,GDP就是对于国民生产消费活动的降维衡量指标,所以他既然降维了自然有损失,能够多么真切的反应经济活动的现实就必然要打个折扣。
经济学里面常用的“降维”的方法就是回归,无论回归在统计学或者其他学科里面被批判的多么体无完肤,但是回归最大的好处在我看来就是最容易融入经济学直觉。在[cref %e5%b0%8f%e7%aa%a5%e2%80%9c%e9%ab%98%e7%bb%b4%e6%95%b0%e6%8d%ae%e9%99%8d%e7%bb%b4%e2%80%9d-2]里面我曾经提到一些最新的高维数据降维的算法,然而算法本身必然是有直觉甚至是(经济)理论来支撑的。当数据挖掘方法被应用在一个经济活动或者经济问题的时候,如果完全脱离了经济直觉和经济思维衍生的分析方法,我觉得未免有点太过于高傲了。有的时候,如果分析思路足够敏锐,那么基于这样思路的各种算法的出来的结果可能是殊途同归。正所谓“万变不离其宗”,这也是我觉得很多data mining的方法应该和经济学、商科的思维更好的融合在一起的缘故。就像挖矿,我们除了要有先进的挖掘机以外,事前的各种勘探和经验思路还是有非常大的价值的,至少可以降低找到金矿位置的成本、尤其是时间成本。这也是我觉得经济学在业界的应用天地断然不仅仅限于和金融相关的那些而已的缘故。
另外,如果“降维”说的广义一点,就是科学的目标。可能不同的人对科学有不同的定义,我除了喜欢一种“概率”角度的定义之外,刚看到一种定义也是蛮受启发的,
The object of science is the discovery of relations.., of which the complex may be deduced from the simple. John Pringle Nichol, 1840
然而,说到底,经济直觉总要来源于实践经验,只要经济学还是定位于“研究人类行为活动的科学”。实践中信息不足的时候,信息是制约的瓶颈,因此我们要借助更多的数学建模工具来力求完美精细的刻画现有的数据构成的轮廓。反之,如果数据是可选择的,那么更多的精力就应该放在如何去“选择”数据上。我认为,实验最大的好处就是数据完全是由实验设计阶段决定的,实验设计的好数据自然会更好的告诉我们所关心的答案。
忘了是哪位大牛在Handbook of Econometrics里面写的了,大意是“与其寻求更好的估计方法,不如寻找更高质量的数据”,言下之意就是在数据可以被“设计”而获得的情况下,我们可以把精力更多的放在实验设计而不是估计模型的选择上。我并不是一个纯粹的reduced form鼓吹者,相反,我是更欣赏structural model后面的经济学思维的。因此,在实验的方法被付诸实践之前,我更希望更多的按照一种经济学model的模式去考量这些问题,去更精巧的让实验告诉我们想知道的答案。除了社会实验的特殊性考量之外,必然的,我们没有任何理由抛弃现有的经济理论、尤其是微观经济理论去完全随意的“检查”几个变量之间的实验上的因果关系。且不论efficiency,社会实验的对象为参与经济活动的人、这一特质决定了我们在设计实验的时候便要充分利用现有对于人类行为的认识成果,更好的一步步设计实验的流程——可能不只是一次实验的流程,更多的是一环扣一环的一个个实验如何按部就班进行下去。一个动态的实验设计会更好的考量实验设计者对于经济学的理解,也是社会实验较之于费歇尔三原则下的自然科学实验、要求更高的方面之一。