这几年一直有对网上交易(中小卖家)是否征税的舆论争议,随便一搜新闻,淘宝就是一个箭靶子——
美帝的eBay日子也不好过...
说到这里,就不得不去翻一下美国税法对于销售税的规定。
--------------下段比较罗嗦,不关心细节这可以跳过-----------
这要起源于上世纪98年,克林顿还在的时候,通过的一项《互联网免税法案》,英文原名是Internet Tax Freedom Act。从wiki上抄一下法案的基本内容:
This law bars federal, state and local governments from taxing Internet access and from imposing discriminatory Internet-only taxes such as bit taxes, bandwidth taxes, and email taxes. The law also bars multiple taxes on electronic commerce.
简而言之,就是联邦和地方政府都不得对互联网接入征税,且不得对比特、带宽和电子邮件征税。翻了翻原始法案文件,第720页开始,到后面说了multiple taxes的定义:
IN GENERAL.—The term ‘‘multiple tax’’ means any tax that is imposed by one State or political subdivision thereof on the same or essentially the same electronic commerce that is also subject to another tax imposed by another State or political subdivision thereof (whether or not at the same rate or on the same basis), without a credit (for example, a resale exemption certificate) for taxes paid in other jurisdictions.
简单理解一下(sorry,我不是学法律的,很可能不准),就是多州不得对一项电子商务交易重复征税。2007年的时候,这项法案延续到2014年11月1日(Internet Tax Freedom Act Amendment Act of 2007)。而实践上,大多遵循1992年的一项最高法院的裁决:
In Quill Corp. v. North Dakota, the Supreme Court ruled that a business must have a physical presence in a state for that state to require it to collect sales taxes.
-------------罗嗦完毕-------------
也就是说,只要没有实体店,州政府就不能强制征收消费税。有趣的就是2013年,市场公平法案(Marketplace Fairness Act ),主要内容就是对虚拟商店也要征收消费税或者使用税。众议院目前还没表决。
[声明]:下面关于eBay的知识均来源于互联网及其他公开渠道,与本人工作无关,在这里只是陈述。所有结论由文章作者负责,不代表公司观点。
那在eBay上,现在的销售税是怎么征收的呢?
Normally buyer do NOT pay tax on eBay unless the following 3 criteria all meet:
- The seller is a Business seller.
- The seller has a physical presence in buyer’s shipping address state.
- That state charges sales tax.
也就是说,只有从eBay上的在买家所在州拥有实体店的商业卖家那里买东西、且该州征税,那么消费者才需要为此付税。一般的案例就是Macy‘s或者bestbuy这样在eBay上开网店的。所以一般在eBay上买东西的时候,结帐是看不到sales tax这一项的(美国都是价外税,如果有销售税会在账单上写明的)。这么看,线上卖家就比线下卖家多了免付税这个优势(虽然征税是直接针对消费者征收的,但是税负的实际承担者取决于供给和需求曲线的弹性)。直白的讲,如果我在网上买一件东西包邮需要$100,家旁边的店也卖$100,但是我在店里买需要交9%的税(以加州为例),那么如果不急用,我为啥不在网上买呢?
终于铺垫完了背景,现在来看AER 2014年1月刊的一篇paper:
Einav, Liran, et al. "Sales Taxes and Internet Commerce." American Economic Review 104.1 (2014): 1-26.
这篇paper主要就是探讨,当某个州提高消费税率的时候,对实体店和网店的影响是怎么样的。他们用的只是eBay的数据,结论是:
every one percentage point increase in a state's sales tax increases online purchases by state residents by almost 2%,while decreasing their online purchases from state retailers by 3.4%.
也就是说,消费税每上升1%,会导致该州居民网购增加2%、从本地零售商网购减少3.4%(因为需要交税)。下面看一下这个结论是怎么一步步得出的。
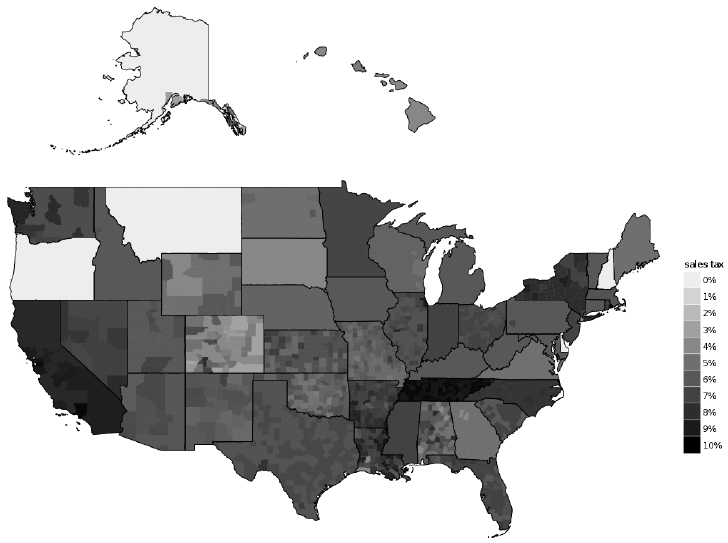
首先看一下美国各州的消费税率: