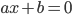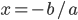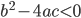在过去的一年中,我给自己定了一个不怎么正式的研究课题:理解美国社会为什么在今天如此分裂和极化。说它不怎么正式,是因为我并不想把它当成一个学术课题来研究。但我还用了研究这个词,可能是更遵循广义的定义——探究和钻研。从我的兴趣点出发,美国当今社会的极化问题可以和另一个著名的历史问题有异曲同工之处——大分流(Great Divergence)。大分流是加州历史学派对中国和欧洲在工业化过程中选择了两条路的描述。美国社会的极化,某种程度上也是一种分流。虽然这两个一个是经济历史问题、一个是政治和意识形态问题,却有一种冥冥之中的缘分,提出了很多思考上的挑战。
试图理解美国社会极化,自然离不开先去复习美国的历史。好在,200多年不是那么漫长,沿着美国宪法这么好的历史脉络按图索骥方便许多。不在此赘述美国的历史了,不过有意思的是,最近的总统大选原来越呈现胶着状态——很多所谓的“摇摆州”,胜负都是1%以内,然后最终决定了美国大选的赢家。其实在以前,美国大选并不一直是如此针锋对麦芒。很多选举的差距其实还挺大的。
选举只是一种民意的体现,反映的是背后的意识形态的分化愈演愈烈。PBS有一部很有意思的纪录片:America's Great Divide: From Obama to Trump(YouTube上可以直接看到完整版),简单回顾了过去十几年的历史。与此同时,无数的经济数据来佐证这种分裂不仅仅是意识形态的分裂,而其背后有着确凿的经济基础的崩裂。比如,美国中产阶级实际收入不升反降(按实际购买力计算)、社会财富分布越来越不均等(近期的例子有2008年次贷危机后,富人的财富反而增加了;此外还可以把时间轴拉得更远来看)、代际间的流动性越来越差(intergenerational mobility,子女超过父母,或者简单地可以叫做“美国梦”,Chetty有很多相当有力的数据)。虽然看数字和证据让人对极化这种现象越来越确信,但是背后的根源到底是什么?说到底,这些都只是显现出来的表象,原因是什么呢?
和“大分流”一样,社会极化的原因显然不是一句两句话就可以讲清的,也不是一个两个学科领域就可以充分解释的。看了很多经济学的观点之后,我开始从其他学科的学者中寻找启发。最近在看Michael Sandel的《The Tyranny of Merit》一书,给出了一些从社会公平和政治哲学角度的解释。
在叙述Sandel的观点之前,我想先说明,我并没有很赞同Sandel给出的处方:比如在藤校等大学录取采用抽签制度。在我看来,这些还是治标不治本,甚至是为了达成某种特定的目的而忽略了可能存在的其他偏颇。不过他这本书值得一读,一是里面涵盖了很多历史渊源,可以帮忙理解很多事情是怎么一步一步演化的。再者,Sandel是个很好的作家,正如他可以把“公正”这么课讲得如此发人深省一样,他这本书写得也是层次递进,诱发思考。一本好书并不是直接说服读者来认同他总结出来的观点,而是精炼出相关的信息素材来帮助读者形成自己的判断。
Sandel一开始就提到了Meritocracy这个看似公平实则事与愿违的制度,可能是造成社会分化的根本原因之一。Meritocracy就是merit-based cracy,而cracy本身是rule或者govern的意思,比如demo-cracy是民主治理,所以meritocracy就是基于人们能力的治理系统。中文翻译大致有“精英政治”或者“贤能政治”,但我感觉不够确切,因为还有elitism等。英文的定义有点繁琐,如下:
Meritocracy is a political system in which economic goods and/or political power are vested in individual people on the basis of talent, effort, and achievement, rather than wealth or social class.
Meritocracy直白的翻译就是“美国梦”(也可以叫英国梦等等),人们只要有能力,就能实现最好的自己。我其实花了很久去理解Meritocracy这个词,主要是一开始不知道Meritocracy相对的是什么。“rather than wealth or social class”其实是一种很模糊的说法,更直接的另一个极端则是,出生决定论(determined by birth)。出生决定其实贯穿了很长的历史,尤其是在中国几千年的封建社会中,君王一定是世袭的,除了科举制度外,其实并没有太多上升通道,农民从一出生就被绑定于土地,人口的地域流动性很低。这里我沿用约定俗成的封建社会定义,即“中国古代战国时代中期开始,到清朝后期(鸦片战争前)”,主要是指历史时段而并不会去跟西方社会的封建制度定义相对比,后者其实是有不少争议的。
西方历史也差不多。最早是君主独裁(Monarchy),然后到了亚里士多德时期的元老院制度(Aristo-cracy),从一个人变成了一小群极其聪明的人。从名字可以看出,Aristocracy和亚里士多德(Aristotle)有着相同的词根Aristo,意为excellent。希腊的先贤们认为Aristocracy的制度优越性来源于少数人拥有的超出常人的治理方面的天赋,而大多数人并没有足够的信息甚至于获取信息的能力。再往后,这种“人尽其才、任人唯贤”的理念就延续到了Meritocracy,而且不仅仅限于政治,可以应用于社会的方方面面,尤其是在这个社会分工高度专业化的时代。
Meritocracy之所以被歌颂,很大程度是是因为它否定了“出身决定论”。一个人只要有能力、肯努力,就能获得某种意义上的功成名就。这样的制度是看似公平的,至少是机会公平的,给予了人民希望。然而最早造出Meritocracy这个词的英国哲学和社会学家Michael Young却有着相当悲观的预测,在其1958年的著作《The Rise of the Meritocracy》里,他预言2034年英国会有一场发育根源的社会起义,因为Meritocracy会造成人们追求智商或者其他优异属性(比如优生学),一旦这些能力变成了可以人为制造的,就会进一步造成社会的分化,回到出生决定的困境。Sandel在书里给出了现实的答案:美国在过去一个世纪中,一直歌颂着美国梦。然而,这种美国梦掩饰了社会分化的残酷,使得成功者过于自负地相信自己的成功是自己的努力所得,而失败者则将失败归咎于能力不足而意志消沉,而忽略了外界因素如制度上的不平等。然而事实呢?Sandel以大学录取举例。美国初高中生需要通过一系列的成就来向大学证明他们的能力,比如sat分数,比如ap课程,比如志愿服务,比如体育,然而这一切其实很大程度上是有家庭背景决定的。高中生很累,因为他们要付出很多努力来获取这些优质的标签,所以他们会觉得这一切都是自己的能力和努力的结果,而忽略或者低估了运气或者家庭的成分。Sandel举的例子是他所任教的哈佛大学,越来越多的本科生认为自己能进入哈佛完全是天赋异禀,而不是其他什么因素。可是残酷的事实是,越来越多的数据表明,这些标签其实反映的并不是学生本人的能力,而是家庭背景,比如SAT分数最相关的因素就是家庭收入,甚至超过了家庭受教育程度的影响。
美国大学录取日趋白热化,反映的其实是美国整个社会制度对于学历的过度依赖。美国只有30%-40%的人拥有大学学位,而在如今的社会分工中,大学学历已经成为了不可逾越的一个门槛,造成了收入的巨大分化,以及相应的社会地位和自我认知的分化。Trump虽然代表的是被全球化抛弃的美国工人阶级,但是他无时不刻不在提醒大家,他是沃顿毕业的高材生、他很聪明、他有能力带领美国。这些Meritocracy最关键的标签被他紧紧地贴在身上,可见Meritocracy已经在美国深入人心。大学不再是单纯的教育机构,而变成了社会分化的筛选器。中文的那句“鲤鱼跃龙门”,成为了最贴切的形容。只不过这里的鲤鱼门不仅仅是靠自己的能力飞跃龙门,而是要靠着家庭等等。
然而Meritocracy这里其实有很多假设。首先,成功与否、尤其是以收入来衡量的成功,代表的真的是人们的能力和自我努力吗?其次,Meritocracy就一定是公平的吗?Sandel又进一步探讨了这两个假设。
对于第一个,收入=个人价值=能力体现(moral deserts),在很多哲学家的讨论中,其实是不成立的。最典型的如哈耶克,他认为人们的收入财富是由市场供给和稀缺性决定的,而不是自我的能力或者对社会的贡献。比如一个对冲基金经理和一个人民教师,后者虽然对社会的道德意义上的贡献可能更高,但是收入远远无法与金融业匹敌。从哲学层面上,哈耶克就否定了收入与merit之间的必然联系。
第二个则是更发人深省的。最初我们认为独裁不公平,是因为世袭,完全由出生决定。我们无法决定自己的出生,这对于个人来说完全是运气因素,所以不公平。那么Meritocracy依赖的merit就完全不依赖运气了吗?我们擅长或者不擅长学习书本知识、运动员擅长或者不擅长体育,如果是基因决定的,那么不也是出生就确定了吗?虽然基因不是家庭财富,但从运气的角度,又有什么本质区别呢?再然后,Meritocracy演化起来,各种筛选制度或者merit可以被人为控制,比如大学录取和优生,被扭曲成一个变相的基于家庭背景的竞争,那么和以前的直接由出生决定又有什么区别呢?即使在最好的情况下,Meritocracy也只是体现了社会分工的最大化,因为从哲学原则上讲,物尽其用人尽其才是实现生产效率最大化的社会资源最优配置(包括人力资源),是一种结果,而其本身并不能意味着可以保证过程的公平。
读到这里的时候,那晚我其实是很悲观的。除了对于Meritocracy背后哲学逻辑的悲观,还有另外一个书中没有提起却让我无法说服自己的问题:公平应当如何对抗人们对于血亲的自私的天性?比如你去问一个人应不应该取消高考而改成自主招生,TA可能会说不行,这样对农村的孩子不公平。然而你去问TA是不是该取消自己孩子的课外辅导班,TA肯定会反对,因为TA还是会在意自己孩子的成绩。这种父母希望自己孩子更能够成功的天性,和人们希望这个社会公平的愿望,在我看来其实是有着内生的矛盾的。假如一个社会真正做到了机会均等,那么就意味着,孩子的成就跟父母是完全独立的,就一定会有孩子跌落社会阶层。但对于父母来说,他们的天性是希望孩子成功的,自然会极尽所能增加孩子成功的概率(北上广中产阶级的教育内卷就是最好的体现),即使他们自己之所以能从农村到城市中产阶级正是受益于高考制度带来的机会公平。在这里,每个人希望社会尽可能的公平的愿景,和希望自己的孩子有更多成功机会的自私自利,是对立的。如果同时看社会中的个体与群体,这就形成了某种意义上的社会层面的“囚徒困境”。每个人都知道社会公平是最好的结果,但没有人希望社会公平的代价是自己的小孩阶层沦落。
或许正因如此,我们看到了美国社会二百多年来代际演化的结果——阶层流动性越来越差,社会财富越来越集中,Meritocracy这种社会制度也不自觉地为社会分化服务着,而并不如人们最初理想化地认为它可以保证机会公平并约束社会分化。如果制度反应的只是人们的天性,而不是制度造成社会分化,那么我对于社会的悲观也就成为一种不可能被改变的注定性事件了。中国古语有云,天下大事,分久必合,合久必分,无非就是说,社会的分化导致财富集中,然后阶级之间失去平衡,对立加剧,最后只能通过暴力手段来重新分配财富和资源,进入下一轮的演化。这好像看来是注定的轮回。
然而过了几日之后,我觉得自己的悲观忽视了几千年来社会的进步。一则,社会分化并不一定是一个零和游戏,即使相对层面的流动不充分,绝对层面我们还是可以实现所有阶级一起进步的,并不一定就意味着两极分化越来越严重。二是,制度并不总是为了服务统治阶级而被创造出来的。人们一直在学习制度,意识到制度的缺陷,然后试图用群体的理智来克服个人的囚徒困境,而不是利用制度的缺陷来最大化个人的利益。人们可以创造一个公共机构来调节机会分布的不均衡。正如政府用税收来实现社会收入的重新分配,机会某种程度上也可以被人为调节,尤其是在整体蛋糕可以被做大的情况下。高等教育的普及、引入其他非学历标签来帮助人们寻找到人尽其才的工作,调节某些行业过高的收入,这些都是帮助在整体增长的同时个体不至于分化加剧的。虽然听起来还是很理想主义,但是人类既然能够从奴隶制自我修正到民主制度,那么进一步的修正也就是时间问题。虽然在我们短短的一生中,只能见证一些边际的改变而已。
当然,Sandel这本书里还有其他很值得阅读和思考的内容。我只是有着自己一个强烈的问题,然后试图去寻找一种政治哲学方面的解释而已。换做不同的问题和思考模式,或许对此书会有不同的感触和解读。对于萦绕我的那个社会极化的问题,我也并没有找寻到所有的答案, 还是会一直探索下去。