最近在家里遵医嘱养伤,闭门不出,倒也是这个特殊时期最好的相处形式。百无聊赖,只能看书以解乏。前面开始读Saez的一些文章,后面索性去扒了一下他这学期的课,系统地看一下public economics(公共经济学,基本就是政府对于经济的各种干预,有别于political economics,政治经济学,主要是研究制度的)这方面的一些研究。(题外话,最近还在看周雪光老师的《中国国家治理的制度逻辑》,也是讲政府如何管理一个国家的,很有中国特色,可以作为美国小政府 vs 中国大政府的补充。等我看完了再另写一篇感受。)
这门课覆盖的主要是税制,因为政府主要是靠征税获得收入(卖地这个好像在美国不是一个选项),从而来实现公共物品的购买(比如修路,军队),以及收入再分配。我还没细细看完每一章节,不过先开始看的反倒是这门课最后一块儿,养老金体系的设计。如果换做我还在读书,那看这些政策可能就是隔岸观火,虽然可以解出来一个数学上的最优选择,却不见得有什么直觉。在美国生活了五年多,多少对这个体系有着自己的理解了,然后再去看学术方面的论文,倒是更容易代入自己的实际体验。
先简单地啰嗦一下401k和IRA,这两个美国最流行的私人养老金账户。以前在中国工作的时候,强制缴纳的是公共账户的养老金,以及公积金。美国对应的则就是Social Security(社会安全金)和养老金的私有账户(401k、IRA之类)。虽然社会安全金是超过2/3美国老人的主要收入来源,但是其数目并不多,而且基本是大锅饭的概念,只能保证最基本的生活水平。退休金则是真正设计来平缓一个人一生的消费,使得其靠这笔钱可以老有所养。
值得注意的是,美国七十年代以前最流行的其实是pension(defined benefit,简称DB,政府或企业的退休金)。相较而言,私有养老金则称为defined contribution,简称DC。这个和私有账户最大的区别是,pension由雇主全权负责承担投资风险,而私有账户则由个人承担投资风险。pension一般是按工作贡献来支付的,所以会跟工作年限、收入等等相关。而私人养老金则是由个人自己存缴,由个人选择投资选项,所以退休之后的账户收益也就取决于个人的存款意愿和投资决策。pension最大的风险就是如果雇主倒闭了,那么可能就没有退休金了。而私人账户则不存在这个问题,盈亏自负。
很多人可能有一个模模糊糊的印象,“美国人爱花钱不爱存钱,他们的钱都是借的”。某种程度上这可以被一部分数据佐证。所以401k和IRA在设计的时候,最重要的激励就是税收优惠。401k前19, 500美金(2020的限额)是可以税前支付的,也就是说这部分钱在当年不需要缴纳个人所得税,其投资收益也是不交税的。IRA也有类似的税收优惠,所以听起来,那肯定是可以存啊。不过也不尽然,401k和IRA在短期之内的流动性都是受限的,59.5岁之前提出是要额外缴纳10%的罚金的。所以整体看来,401k和IRA的设计都是为了鼓励人们现在存钱未来花,而这个未来则是60岁左右的退休年龄。401k另外一个特色就是一般有雇主的match——比如雇员存相当于工资3%的数额,然后雇主也存进去3%,这加起来的6%都是属于个人的,算是公司基本福利之一。美国雇主的平均水平是match 6%的一半,所以还是3%,不过要求雇员要自己存6%才可以。
啰嗦了这么多,我并不是想跟大家建议如何存退休金。稍稍废话。一般说来,如果你每年攒下的钱直接存在没有利息的银行活期账户的话,那还是建议先把401k存满。但是如果有更高的流动性要求(比如攒首付),那么就见仁见智了。一般最少存到雇主免费match的那部分限额(match属于不要白不要的钱),然后多余的在19,500之内自由发挥了。这些都是最最基本的无脑选项。如果想进一步优化,那就要更多计算了。
那么从政府的角度看,401k和IRA存在的意义是什么呢?很显然,政府是想鼓励人们存退休金的。很多人都是一种今朝有酒今朝醉的姿态,等这些人到了无力工作的时候(退休年龄),他们的养老就成为了美国政府的负担,或者其他家庭及社会问题。为了避免老年凄惨的景象,工作年龄时候对401k和IRA的参与就变得额外重要。那么,401k和IRA真的有效地激励了人们去储蓄吗?
Engen-Gale-Scholz的总体数据表明,美国的储蓄率从上世纪70年代的10%已经降到了2000年的0%,虽然在七十年代末401k被引入作为新的养老金体系、且过去的几十年里面401k和IRA的账户存款金额一直在不断上升。猛地一看,那401k和IRA好像没什么作用啊。但是我们不知道的是,如果没有引入401k和IRA,那美国的储蓄率会不会降得更惨呢?此外,他们还发现,整体来说,401k和IRA加上pension账户的总额是挺稳定的,所以看起来好像只是“挤出效应”,即401k和IRA替代了原有的pension存款。
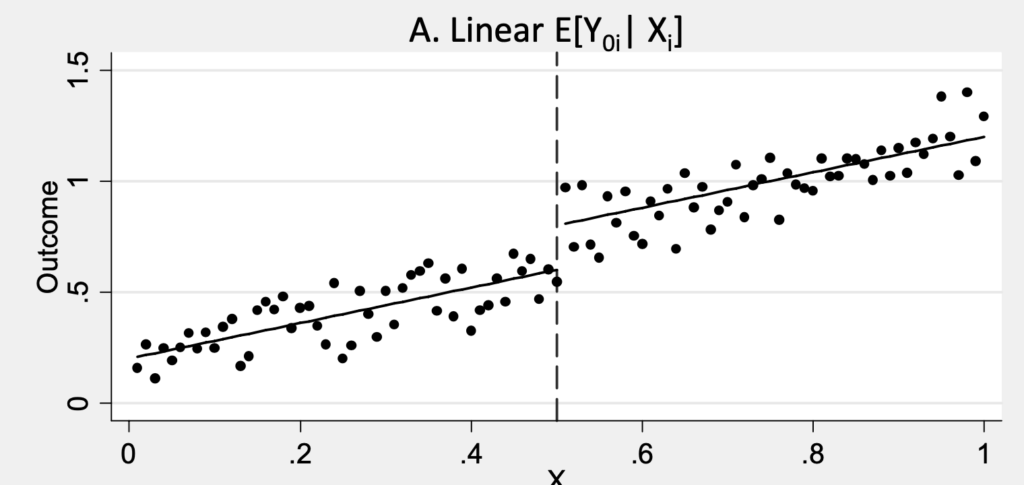
进一步研究401k和IRA其实挺难的,因为几乎没有办法来随机分配401k和IRA的参与条件从而直接估计401k和IRA的效应。退而求其次,可以通过observational data来做回归,不过由于缺失变量问题,回归的结果对控制变量的变化很敏感。再者,可以通过natural experiment来看,比如1982年401k和IRA项目从没有pension的人群扩展到所有人。可以算一个diffence-in-difference估计,不过好的数据也很有限。Poterba-Venti-Wise通过回归发现,符合条件的人会呈现更多的总财富,当然有控制一些相关的变量。但是这其中还是有自我选择的问题——好的雇主可能更倾向于提供401k,或者对财富更敏感的雇员会自我选择参与401k。此外,符合条件的和不符合条件的人们之间的财富鸿沟也是巨大的,比401k账户的金额大得多,所以很难说这到底是人们确实是增加了储蓄意愿,还是只是自我分群罢了。Gelber AEJ:EP ’11最近的研究利用了很多企业有1-2年的401k等待期间(刚开始不可以加入401k,工作几年之后才可以),作为一个外生的制度来源。结果不是特别精确(毕竟数据本身噪音很大),不过还是指向了“挤出效应”,即替代了其他本身所有的储蓄选项。
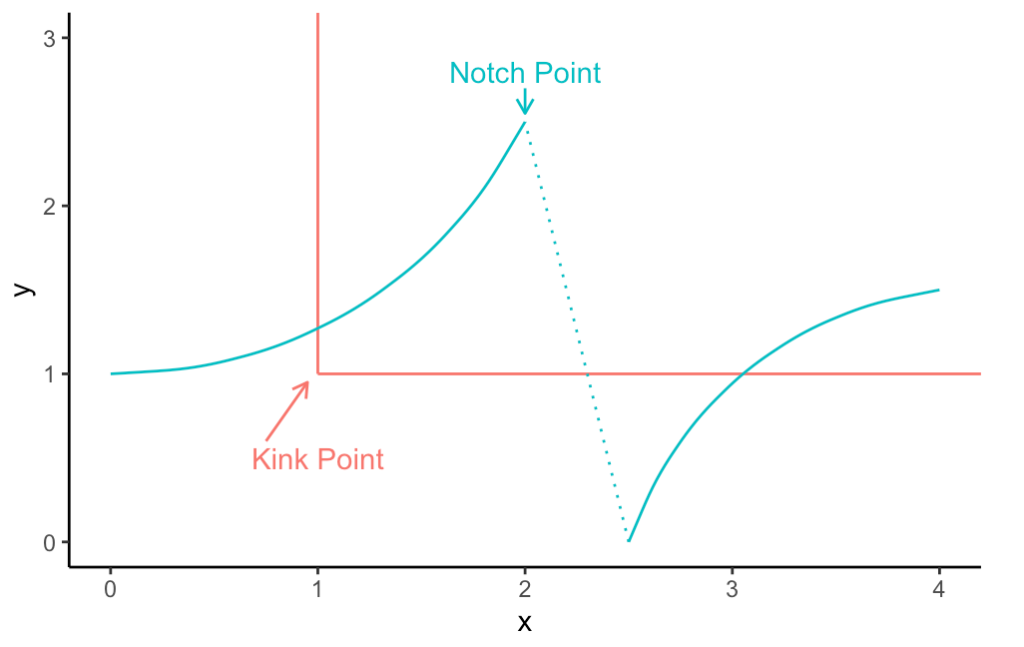
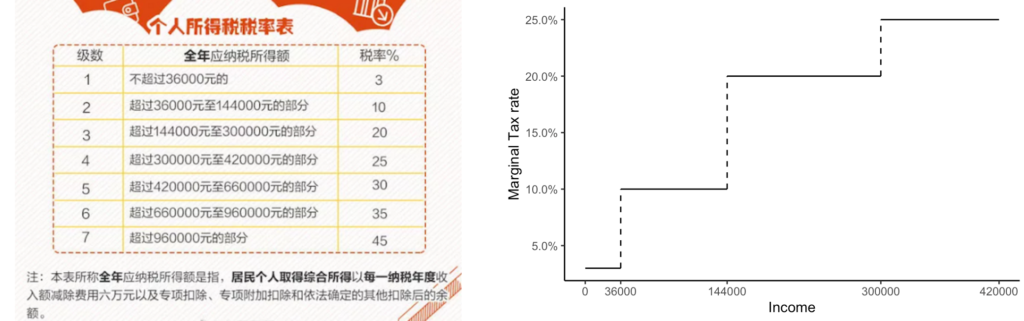
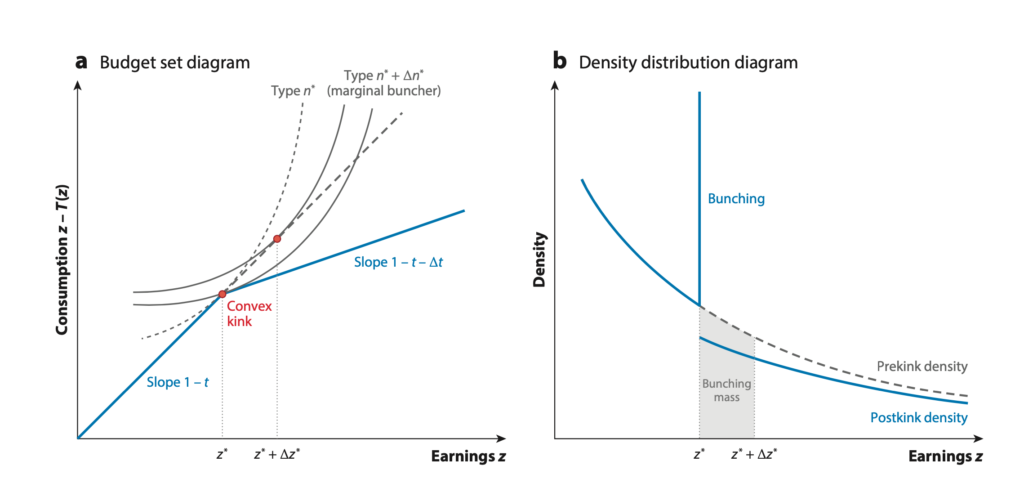
从制度设计的角度,有了401k和IRA,如何让人们参与进来呢?所以下一个问题是,什么激励可以有效地提高人们对401k和IRA的参与率呢?首当其冲的,自然就是雇主的match(配比存款)。免费给的钱,不要白不要对嘛。不过也很显而易见的,在match的比例过后,有一个很大的变化(即上两周提到过的bunching聚集现象)。对于match,大家最大的顾虑就是,这可能只是单单替代了本应有的其他存款,而不见得会增加人们的储蓄总量。此外,match可能是在扭曲人们本来的最优储蓄选择,不见得有效率。从雇主的角度而言,他们为什么提供match呢?一种解释是,401k为了保证公平,有一个 高薪职员 v.s. 其他职员的参与要求。如果非高薪职员参与率过低,那么高薪职员也不能享受401k 的好处,所以企业为了提高非高薪职员的参与率,便提供了match作为一种激励。另一种解释是,有一部分职员知道自己会有自我控制的问题(毕竟钱花出去比存起来爽),所以match成为了一种事前的激励机制,从而使得这部分人也主动储蓄。进一步的一些研究发现,match越简单越好,而且match比等效金额的事后返还(rebate)效果更好(人们的心理作用,对能立刻拿到手的反馈更明显)。
那么人们是否参与、存多少钱,真的是一个理性的选择吗?人大都有惰性,而退休金这套系统说实在的,其实挺复杂的,我也是看了很多分析才大概明白其中脉络。此外,说白了操作空间也就那么一点点,而人生则有诸多不确定性。与其纠结其中,很多人更关心的可能是如何“开源”而不是“节流”吧?下面就是一些人们很懒的证据。
- 很多雇主提供自动参与而不是手动的选项,即默认员工是参与401k和IRA的,要退出反而要有额外额操作。Madrian and Shea (2001)发现,自动参与极高地提升了短期参与率(+60%),并在长期之内保持了一定效果(+30%)。不过,大部分员工是并不会去也改变默认的储蓄数字,就算长期看来这样的选择并不是最优的。看到这里,总结出来的就是,人们非常懒,懒得去理解这套系统到底怎么运作,给什么是什么。
- 还有一种情况是雇主强制员工参与储蓄计划,分为两种形式;雇主默认存一定比例,和雇主强制从员工的工资中扣除一定比例。Card and Ransom Restat’11发现,这两种选择并不是等价的。如果强制从员工工资中扣除,每多扣除一块钱会减少自愿储蓄0.7块;而如果是自己强制存入员工账户,则每多存一块钱只会减少自愿储蓄0.3块。这一实证结果表明,强制储蓄并没有1:1的挤出自愿储蓄,而强制储蓄的形式也会有所影响。可能的一个解释还是,人们非常懒,懒得去看。如果从工资中扣钱了,那他们更有可能会注意到,从而调整自愿储蓄的部分。否则,就不理会了。
Chetty et al. ’14用丹麦的数据证实了另外一个层面,主动vs被动储蓄计划。在企业自动帮雇员储蓄和通过税收优惠激励个人储蓄之间,前者的作用要强得多,有85%的人非常被动,根本不关心。剩下15%会去利用税收优惠, 不过挤出的是他们本来的储蓄,而不会净增新的储蓄。Choi, Laibson, Madrian ’07也证实了人们的惰性——当雇主提供不同的投资选项的时候,人们往往是接受默认的安排。而在员工离职的时候,小金额的存款会被直接转入其个人帐户,结果人们往往将其直接消费掉而不是继续存着。
影响人们储蓄行为的另外一个因素可能是peer effect。如果周围的人都在存钱或者讨论这件事情,那么个人是不是会更有可能存钱呢?答案是肯定的。Duflo and Saez, QJE ’03发现peer effect对人们去不去参与关于401k的讲座是有效果的,而参与讲座本身、更多的了解401k的运作机理对人们储蓄的决定也是有效果的。只不过,相比于“默认选项”来说,这些效果都要小的多。正因为人们对待退休金储蓄这个决定有太多行为上的因素(懒)而不仅仅是钱上的考量,更便宜地促进人们储蓄的手段往往是简化流程或者其他手段来降低交易成本(比如学习401k如果运作也是有成本的),而不是单单提供金钱上的激励。
看完这一课,我最大的感触是,怪不得周围很多人对401k闻之色变。确实,像我这样在学校里面正儿八经学过一些财务知识和税法的,都觉得美国401k的设计其实挺复杂的,细细算起来并不容易。换成他人,花这么多时间和痛苦来优化一项未来都不知道会怎么样的决定,确实有点得不偿失了。默认就默认吧,不会太亏就行了呗。更有意思的是,每次我稍稍科普401k的知识,对方多多少少都有一副羞愧的表情,好像自己对自己很不负责似的。我想说,现在有数据了,其实人们都是这样!真花力气去搞这些事情的是极其少数,而且八成也没啥本质变化。除非真的对这个系统感兴趣,否则花太多时间可能真的是,不值得。