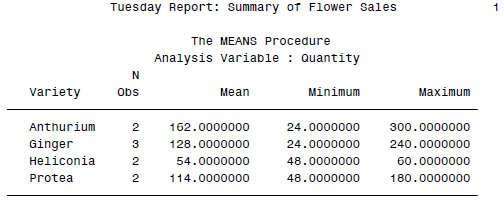
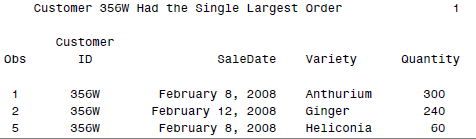本系列连载文章:
数据集操作永远是逃不掉的问题,最简单的就是两个数据集的合并——当然不是简简单单的行列添加,按照某一主键或者某些主键合并才是最常用的。在SAS中,要熟悉的就是SET这个声明,可以用改变数据集等等。
生成新变量
这里一个比较简单的例子,就是有一个现成的数据集,我们想增加一个变量。
DATA averagetrain;
SET 'c:MySASLibtrains';
PeoplePerCar = People / Cars;
RUN;
PROC PRINT DATA = averagetrain;
TITLE 'Average Number of People per Train Car';
FORMAT Time TIME5.;
RUN;
这样的结果就是增加了一个新的变量PeoplePerCar:
Average Number of People per Train Car
Obs Time Cars People PeoplePerCar
1 10:10 6 21 3.50000
2 12:15 10 56 5.60000
3 15:30 10 25 2.50000
4 11:30 8 34 4.25000
5 13:15 8 12 1.50000
6 10:45 6 13 2.16667
7 20:30 6 32 5.33333
8 23:15 6 12 2.00000
行合并
这里比较类似于R里面的rbind()函数,就是直接在尾部附上后面的数据。当SET指定了两个或多个数据集的时候,可以进行这样的操作。距离如下:
* Create a data set, both, combining northentrance and southentrance;
* Create a variable, AmountPaid, based on value of variable Age;
DATA both;
SET southentrance northentrance;
IF Age = . THEN AmountPaid = .;
ELSE IF Age < 3 THEN AmountPaid = 0;
ELSE IF Age < 65 THEN AmountPaid = 35;
ELSE AmountPaid = 27;
PROC PRINT DATA = both;
TITLE 'Both Entrances';
RUN;
然后结果输出为:
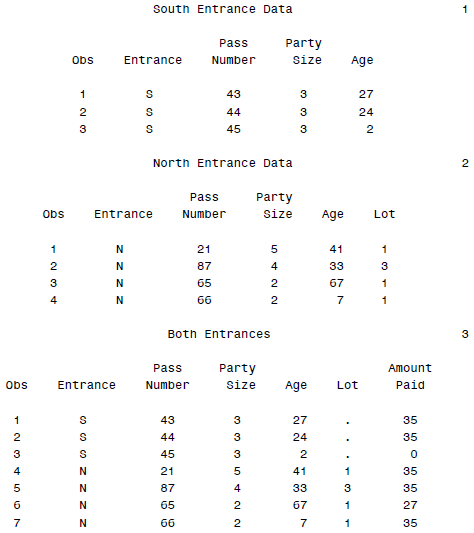
这里很容易看出,对于第一个数据集没有的变量LOT,会自动添加缺失值。
SET还可以进一步结合BY对数据排序:
DATA interleave;
SET northentrance southentrance;
BY PassNumber;
PROC PRINT DATA = interleave;
TITLE 'Both Entrances, By Pass Number';
RUN;
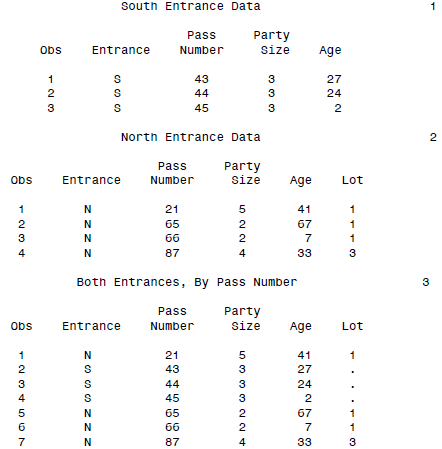
SAS一对一合并数据集
类似于SQL的join和R的merge,SAS也可以合并数据集。先从最简单的一对一合并说起:
* Merge data sets by CodeNum;
DATA chocolates;
MERGE sales descriptions;
BY CodeNum;
PROC PRINT DATA = chocolates;
TITLE ”Today's Chocolate Sales”;
RUN;
这样就可以得到按照CodeNum来合并这两个数据集了,返回结果为:

当然一对多也是可行的。
原数据为:
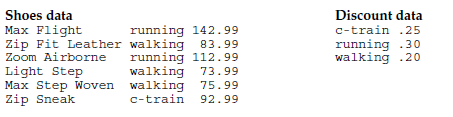
然后代码为:
* Perform many-to-one match merge;
DATA prices;
MERGE regular discount;
BY ExerciseType;
NewPrice = ROUND(RegularPrice - (RegularPrice * Adjustment), .01);
PROC PRINT DATA = prices;
TITLE ’Price List for May’;
RUN;
最后得到的结果就是:
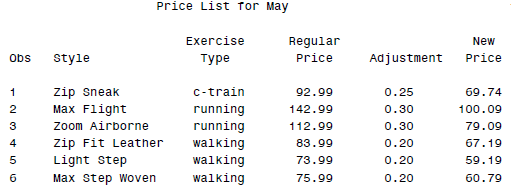
有的时候我们还想把一些统计量也合并进来,比如PROC MEANS得到的那些,这样自然也是不怎么麻烦的。
DATA shoes;
INFILE ’c:\MyRawData\Shoesales.dat’;
INPUT Style $ 1-15 ExerciseType $ Sales;
PROC SORT DATA = shoes;
BY ExerciseType;
RUN;
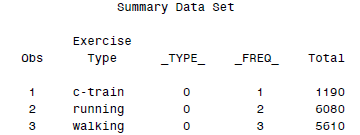
* Summarize sales by ExerciseType and print;
PROC MEANS NOPRINT DATA = shoes;
VAR Sales;
BY ExerciseType;
OUTPUT OUT = summarydata SUM(Sales) = Total;
PROC PRINT DATA = summarydata;
TITLE ’Summary Data Set’;
RUN;
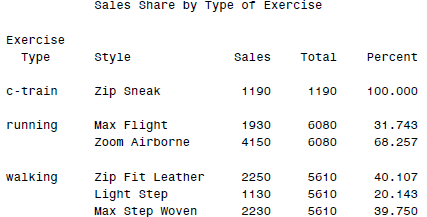
* Merge totals with the original data set;
DATA shoesummary;
MERGE shoes summarydata;
BY ExerciseType;
Percent = Sales / Total * 100;
PROC PRINT DATA = shoesummary;
BY ExerciseType;
ID ExerciseType;
VAR Style Sales Total Percent;
TITLE ’Sales Share by Type of Exercise’;
RUN;
这里用到了OUTPUT输出统计结果到SAS数据集,这样最后结果就是:
还有一些特定的情况,可以不用MERGE而是UPDATE,这个就得稍稍小心一点了...
* Update patient data with transactions;
DATA perm.patientmaster;
UPDATE perm.patientmaster transactions;
BY Account;
PROC PRINT DATA = perm.patientmaster;
FORMAT BirthDate LastUpdate MMDDYY10.;
TITLE 'Admissions Data';
RUN;
基本就是把patientmaster这个数据集用transactions里面有的数据覆盖掉相应的记录。

SAS里面拆分数据
在读入数据的时候,SAS还可以自动按照某些条件把其拆分为两个数据集,这里需要调用OUTPUT声明。
DATA morning afternoon;
INFILE 'c:\MyRawData\Zoo.dat';
INPUT Animal $ 1-9 Class $ 11-18 Enclosure $ FeedTime $;
IF FeedTime = 'am' THEN OUTPUT morning;
ELSE IF FeedTime = 'pm' THEN OUTPUT afternoon;
ELSE IF FeedTime = 'both' THEN OUTPUT;
RUN;
PROC PRINT DATA = morning;
TITLE 'Animals with Morning Feedings';
PROC PRINT DATA = afternoon;
TITLE 'Animals with Afternoon Feedings';
RUN;
得到的就是两个数据集(虽然我们读入的只有一个...你也可以理解为生成了两个原数据集的子集):
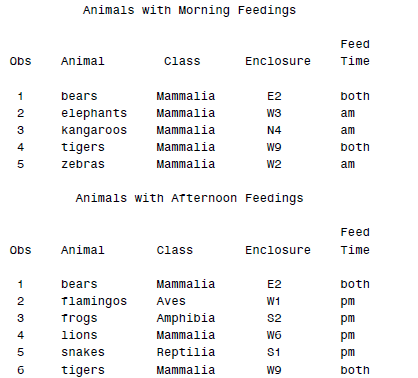
这里就类似于R里面的split()函数了。
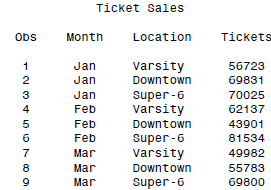
还有一些数据格式比较不稳定,比如一行多条记录:
Jan Varsity 56723 Downtown 69831 Super-6 70025
Feb Varsity 62137 Downtown 43901 Super-6 81534
Mar Varsity 49982 Downtown 55783 Super-6 69800
这个时候就可以利用OUTPUT的操作,来逐行读取并输出:
* Create three observations for each data line read
* using three OUTPUT statements;
DATA theaters;
INFILE 'c:\MyRawData\Movies.dat';
INPUT Month $ Location $ Tickets @;
OUTPUT;
INPUT Location $ Tickets @;
OUTPUT;
INPUT Location $ Tickets;
OUTPUT;
RUN;
PROC PRINT DATA = theaters;
TITLE 'Ticket Sales';
RUN;
最后得到的数据就相当规范了(我在想为啥SAS可以有这么多奇葩的数据输入...真折磨人啊):
SAS里面变量选取等参数
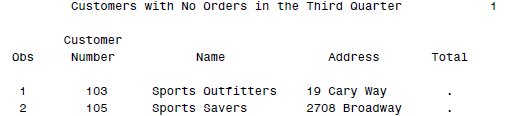
其实DATA里面的参数还是蛮多的,除了以前提到过的KEEP,DROP,还有可以重命名的RENAME等。还有一个比较有用的可能就是IN了:
DATA noorders;
MERGE customer orders (IN = Recent);
BY CustomerNumber;
IF Recent = 0;
PROC PRINT DATA = noorders;
TITLE ’Customers with No Orders in the Third Quarter’;
RUN;
这样可以增加一个新的变量Recent,来记录某条记录是否被合并。
WHERE的用法也可以稍稍赘述一下:
*Input the data and create two subsets;
DATA tallpeaks (WHERE = (Height > 6000))
american (WHERE = (Continent CONTAINS ('America')));
INFILE 'c:\MyRawData\Mountains.dat';
INPUT Name $1-14 Continent $15-28 Height;
RUN;
PROC PRINT DATA = tallpeaks;
TITLE 'Members of the Seven Summits above 6,000 Meters';
PROC PRINT DATA = american;
TITLE 'Members of the Seven Summits in the Americas';
RUN;
这样得到的结果为:

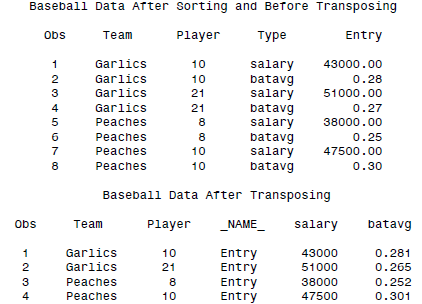
SAS中数据的转置:TRANSPOSE
数据的转置有时候也是逃不掉的。这里就有些类似于R里面的reshape()函数了,但是肯定没有reshape2里面的melt and cast强大...我一度觉得reshape2的用法很麻烦,后来才发现原来这东西真的强大到一定程度了...
DATA baseball;
INFILE 'c:\MyRawData\Transpos.dat';
INPUT Team $ Player Type $ Entry;
PROC SORT DATA = baseball;
BY Team Player;
PROC PRINT DATA = baseball;
TITLE 'Baseball Data After Sorting and Before Transposing';
RUN;
* Transpose data so salary and batavg are variables;
PROC TRANSPOSE DATA = baseball OUT = flipped;
BY Team Player;
ID Type;
VAR Entry;
PROC PRINT DATA = flipped;
TITLE 'Baseball Data After Transposing';
RUN;
结果为:
SAS里面自带的变量
SAS里面有些默认自带的变量,有时候用起来还是蛮方便的,类似于R会自带一个row.names这种变量。
比如_N_就会加上行号(当然有时候也不是,呃,准确的说应该是SAS执行的循环顺序,说了SAS是一行行操作数据的嘛):
DATA walkers;
INFILE 'c:\MyRawData\Walk.dat';
INPUT Entry AgeGroup $ Time @@;
PROC SORT DATA = walkers;
BY Time;
* Create a new variable, Place;
DATA ordered;
SET walkers;
Place = _N_;
PROC PRINT DATA = ordered;
TITLE 'Results of Walk';
PROC SORT DATA = ordered;
BY AgeGroup Time;
* Keep the first observation in each age group;
DATA winners;
SET ordered;
BY AgeGroup;
IF FIRST.AgeGroup = 1;
PROC PRINT DATA = winners;
TITLE 'Winners in Each Age Group';
RUN;
这样得到的结果就是排序后的次序了:
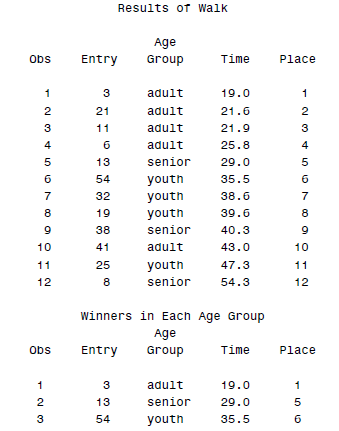
类似的变量还有FIRST.variable和LST.variable,这里由于我们用到了 FIRST.AgeGroup,所以第二次输出的时候只有第一个AGE GROUP的结果。

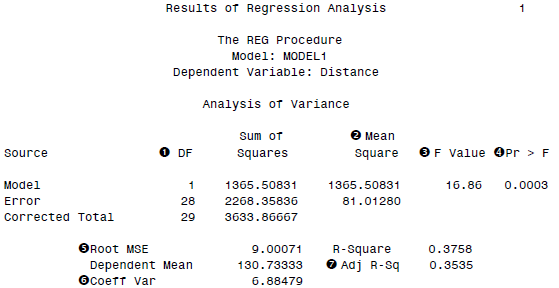

 to the OUTEST= data set
to the OUTEST= data set