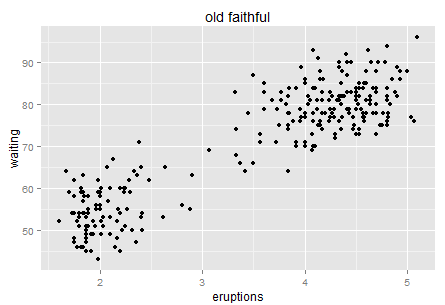
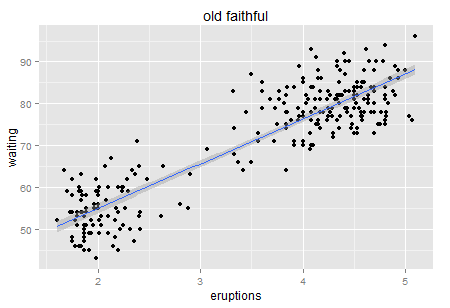
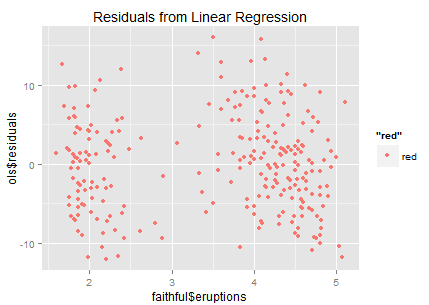
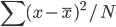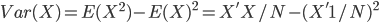以前来美国都是出差,反正公司管吃管住,大部分东西都不怎么操心,其实还是挺不一样的。这次是真的搬过来了,就要跟各个政府部分打交道,此时才算是真正和这个社会制度开始打交道。
我是一种对美国既不喜欢也不讨厌的状态。这次搬过来也只是想换个环境增加一点人生阅历,并非抱着一种特别崇敬的心情来看的(也可能是在欧洲待过之后已经明白了“外国的月亮也不总是圆圆的”那样的道理)。
税收制度。我现在接触到的还只是个税。美国的个税是真正意义上的“所得税”,允许有很多项目的抵扣,而不像中国的个税基本就是一个“流转税”,按工资流水交完了就完了。以前觉得欧洲税高,现在看美国税率也不低,乱七八糟扣完了手里真没什么钱了(加州有州税)。说到州税也就是美国特色的联邦-州政府制度。中国虽然是有国税和地税之分,但至少在个人所得税这里我们只需要交一次就好了。美国就要两层盘剥(取决于每个州的税制),包括法律也是,每个州都有自己的法律。而且对个人来讲最崩溃的就是要全球交税——比如我在中国有房租收入,按税法那也要交美国的税(中国已经交过的可以抵扣)。
社保。社保某种意义上就是交税,这个全球各个国家都类似,我还真没看到哪里是真正的“现收后付”,基本都是“现收现付”吧。美国乱七八糟的社保交了一堆然后发现医保还是额外买的,我至今也没太搞明白扣的一堆都是什么钱,就当交税了吧。反正在上海也是扣8%社保2%医保什么的。我刚来没几天就跑到社会安全局那里去办理ssn了,美国好像没有身份证号一说,反正ssn大概是最好的个人识别的方式了,办银行卡啊什么都靠这个。但是这东西又不象国内的身份证那样可以当证件用,这个号码居然是要保密的,这张卡也就是薄薄一张纸片,需要藏起来....
投票权。反正这个是建立在交税基础上的,刚来不久就收到呼吁停止扩建milpitas垃圾场的传单。民主有民主的玩法。
信用制度。这是除了民主之外大家羡慕美国最多的?反正我还没觉得这东西有啥特殊...
驾照。DMV应该是我到了加州之后跑的次数最多的地儿了。有意思的是,DMV除了处理跟车和驾照有关的东西,还可以申请一张id,非驾照的id。还有就是出门就要开车,这个挺讨厌的。
地址。美国好像办什么东西都特别看重地址。开银行账户需要提供带有地址的文件,办理驾照什么也都靠地址,信用卡网上购物还要验证billing address(以前用国内信用卡海淘的时候这个都是随便过的)。搬家了要通知劳工局,要通知银行,要通知dmv等等,然后美国寄东西也是奇慢无比的,习惯了国内的“江浙沪包邮次日到”只能默默的去搞个amazon prime来实现two day free shipping了。哎。还我顺丰...
房租。湾区房租贵的离谱,哎。2k刀都不一定找得到一室一厅住起来还算放心的房子。至于日常物价什么的,倒是和出差没什么两样,最多就是去超市买东西的次数多了一些。
社交。开车就没得喝酒,好像湾区人民都是过的家庭生活,下班也没见谁去喝酒,除非是生日趴什么的。倒是大大小小的各种meetup一堆堆的,可见大家晚上还是挺无聊的,需要一些活动来打发时间。
好像也没啥了,一个整天上班下班的人应该有啥可以说的呢?美国又不是欧洲,随处走走都是艺术建筑什么...