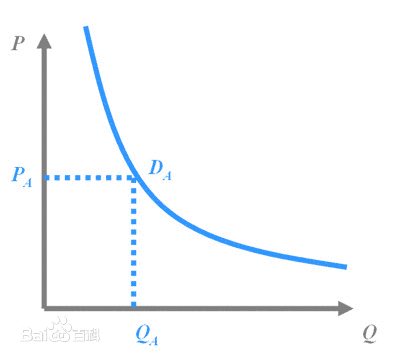
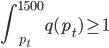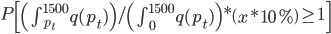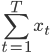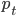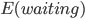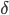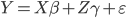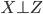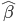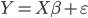我现在的笑点好像越来越低了...
| AB_Test | Post_Stratification | Post_Strat_rescale | HTE | HTE_rescale | |
|---|---|---|---|---|---|
| (Intercept) | 20.85 (0.37)*** | -0.61 (0.04)*** | 20.85 (0.03)*** | 0.40 (0.03)*** | 20.85 (0.03)*** |
| TCT | 4.02 (0.52)*** | 4.02 (0.05)*** | 4.02 (0.05)*** | 2.01 (0.05)*** | 4.02 (0.04)*** |
| pre_x | 1.05 (0.00)*** | 1.00 (0.00)*** | |||
| pre_x_rescale | 1.05 (0.00)*** | 1.00 (0.00)*** | |||
| TCT:pre_x | 0.10 (0.00)*** | ||||
| TCT:pre_x_rescale | 0.10 (0.00)*** | ||||
| R2 | 0.00 | 0.99 | 0.99 | 0.99 | 0.99 |
| Adj. R2 | 0.00 | 0.99 | 0.99 | 0.99 | 0.99 |
| Num. obs. | 20000 | 20000 | 20000 | 20000 | 20000 |
| p < 0.001, p < 0.01, p < 0.05 | |||||