这个纯属做出来卖萌的...只是画出来有高有低比较像琴键的感觉,又按照类别填了一下颜色,所以再卖弄一下来个好听的名字——七彩琴键图。
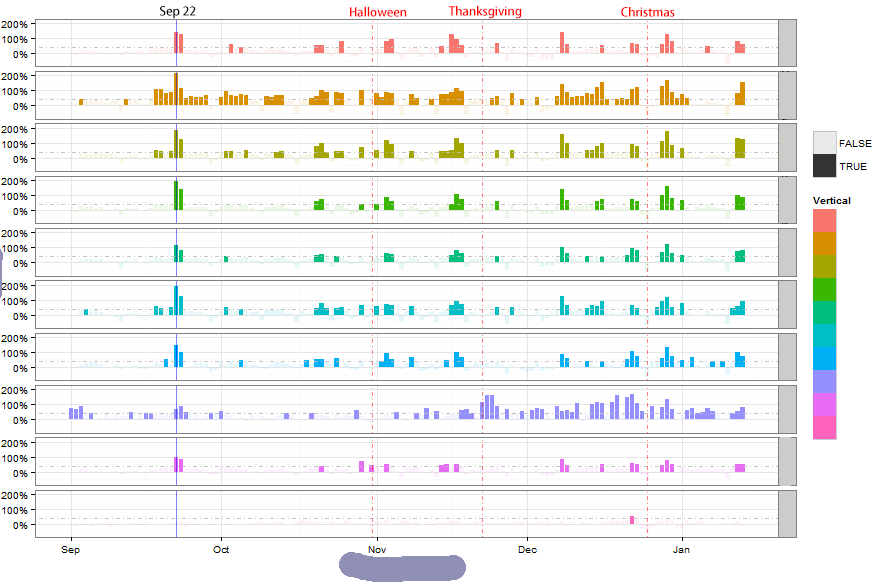
数据比较敏感,所以很多信息都删掉了...大概还是可以看出来横轴是时间,纵轴是增长率。增长率大于阈值40%则100%上色,否则设为半透明。颜色是ggplot2自己上的,还是挺美观的...从上而下,各个类别的表现比较容易直接区分,这也就是这张图的目的。此外标注了一些重要日期。
可能一般画增长率都会画折线图吧,我只是觉得同样的数据折线图画出来大起大落的太丑了,还是这样好看一些...
最后按惯例,放上代码。其实很短...
library(ggplot2)
require(scales)
# growth
ggplot(q4_yoy, aes(x=DT12, y=ll, color=NULL))+
geom_bar(stat = "identity",aes(fill=Vertical,alpha=ll>0.4))+ #柱状图,然后判断是否大于40%
scale_y_continuous(labels = percent_format())+ #纵轴改成百分比
facet_grid(Vertical~.)+ #分类别画出来
geom_hline(yintercept=0.4,alpha=0.9,color="grey",linetype="dotdash")+ #40%增长率的水平线
geom_vline(xintercept=as.numeric(as.Date("2012-10-31")),
alpha=0.5,color="red",linetype="dotdash")+ #一些重要的日期
geom_vline(xintercept=as.numeric(as.Date("2012-11-22")),
alpha=0.5,color="red",linetype="dotdash")+
geom_vline(xintercept=as.numeric(as.Date("2012-12-25")),
alpha=0.5,color="red",linetype="dotdash")+
geom_vline(xintercept=as.numeric(as.Date("2012-09-22")),
alpha=0.5,color="blue",alpha=0.5)+
# annotate("text",label="Sep 22",x=as.Date("2012-09-22"),y=-0.5)+
theme_bw()#黑白底板
