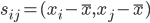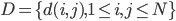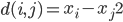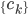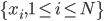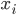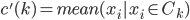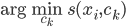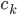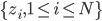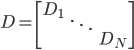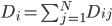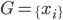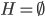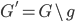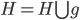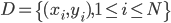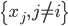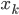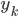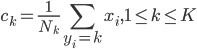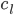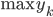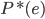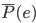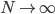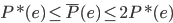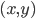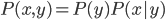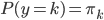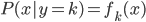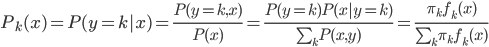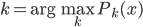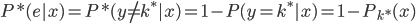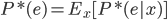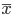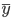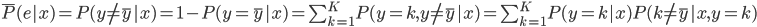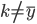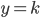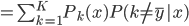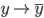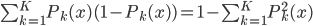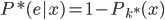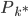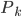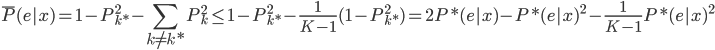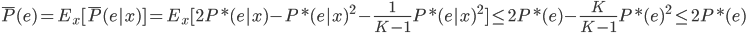好吧,我在eBay折腾的最多的就是生成自动化报告时候各种软件之间的相互调用,什么R啊,SAS啊,Teradata啊,Excel啊,Python啊,反正基本都有机会相互调用一下。每到此时我就深深感慨选择一个library丰富的工具是多么的重要!You could hardly expect what you colleagues are handy with!(P.s. 不要跟我提VBA这种逆天存在的东西。有哪个时间研究它你学点啥别的不好...)
今天忍无可忍+心情大好的折腾了一下R和excel。这个不是简单的从R里面读写excel数据,而是真心用R去操纵excel里面的单元格(cell),除了读写数据之外还要定义样式什么的。excel作为一个奇葩的软件,you may never expect where people would paste data to! 然后他们再自定义一堆样式(我恨这种点点鼠标就能改的东西,你丫又不是Photoshop...)。
但是没办法,人家定义好的“高端洋气”的报表姿态你不能轻易动啊。只能乖乖的往里面paste数据。这件事虽说一次两次手动也就罢了,三五次真的是要疯掉的。anyway,万事总有解决的途径...
很久以前从Yixuan 的博客上得知有xlsx这么个包,当时只记得这东西可以读写xlsx...直到后面折腾了一下才知道这货底层居然调用的是java的xlsx API,也就是说不用写Java也可以操作xlsx了,yeah!
为了生成excel格式的自动化报告(不要问我为啥不用knitr,不用***,说起来都是泪呀!),我主要需要解决的就是:
- 读取原有xlsx文件,保持格式、附加新格式。
- 在相应的位置粘进去新的数据。(当然如果只有这么一个需求可以通过ODBC来做...)
第一个倒是满简单的,就是较之yixuan代码里面的createWorkbook(),改成loadWorkbook()就可以了。然后就是找到相应的sheet,这个也满简单的,一行getSheets搞定。
然后第二步建议不要去操作cell(太没效率了),直接操作cellblock。CellBlock()可以用来定义一个新的CellBlock,然后灵活运用CB.setBorder()和CB.setColData()就可以先增加边框、然后一列列填充数据。这里使用按列填充数据主要是因为R里面的Data Frame是一列一个数据格式的,一下子把一块儿都paste到excel的cellblock里面的话,会报错...BTW为了定义边框的样式,需要用到Border()。类似的还可以定义Fill和Font这些。
同上,最好不要直接用addDataFrame()来直接贴数据...格式不能覆盖。如果是要在一个新的sheet上贴数据,那么就write.xlsx(sheetName="newsheet",append=T)好了。不需要通过上述底层的API折腾了。
最后还有一个比较有用的函数,autoSizeColumn()可以用来自动调整列宽。全鼓捣完之后saveWorkbook()保存就可以啦。
最后的最后,一个珍贵的建议——都在R里面把数据整理好再去想输出到excel里面(什么reshape2啊,data.table啊,plyr啊,该上的一起上啊!),千万别手贱在excel里面改一点点小东西...每一次都手动改一下下你的时间就被白白浪费了好几分钟!珍爱生命,远离excel...
附上一段我最后搞定自动化报告的代码:
library("xlsx")
test_template <- loadWorkbook("template.xlsx") #读入template.xlsx文件。定义好各种乱七八糟的格式的。
design_tab <- getSheets(test_template)[["design"]] #转到design这个sheet。
data_block <- CellBlock(design_tab, 5,5,nrow(mydata),ncol(mydata)) #准备贴数据的方块,我这里从第5行第5列开始贴。
border <- Border(color="black", position=c("LEFT", "RIGHT"),
pen=c("BORDER_THIN", "BORDER_THIN")) #定义边框样式——左右黑色细直线。
for (i in 1:ncol(mydata))
{
CB.setBorder(data_block, border,colIndex = i,rowIndex=1:nrow(onetime_design_tab)) #给每一列都贴上边框
CB.setColData(data_block, mydata[,i], i, rowOffset=0, showNA=F, colStyle=NULL)#给每一列贴数据
}
border_bottom <- Border(color="black", position=c("LEFT", "RIGHT","BOTTOM"),pen="BORDER_THIN") #定义结尾行样式——底端黑细直线
data_block_bottom <- CellBlock(design_tab, 5+nrow(mydata),5,1,ncol(mydata)) #选择最后一行
CB.setBorder( data_block_bottom, border_bottom, 1, 1:ncol(onetime_design_tab)) #定义最后一行格式
autoSizeColumn(design_tab, 5:(5+ncol(onetime_design_tab)))#调整列宽
saveWorkbook(test_template, file=output_xlsx_name) #保存
##add row data
write.xlsx(rawdata, file=output_xlsx_name, sheetName="raw_data",append=T,row.names=F) #直接贴原始数据,无格式
###add queries
R_file <- readLines(R_file_name, n=-1) #直接贴R代码
SQL_file <- readLines(SQL_file_name, n=-1)
write.xlsx(SQL_file, file=output_xlsx_name, sheetName="query_SQL",append=T,row.names=F) #直接贴代码到新的sheet中
write.xlsx(R_file, file=output_xlsx_name, sheetName="query_R",append=T,row.names=F)