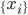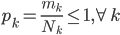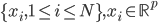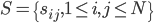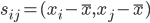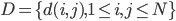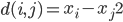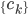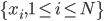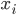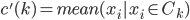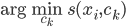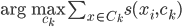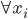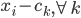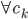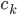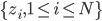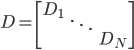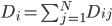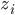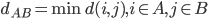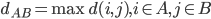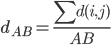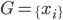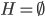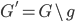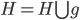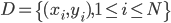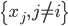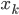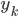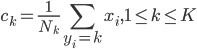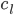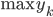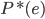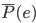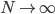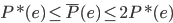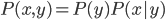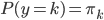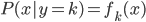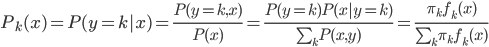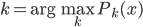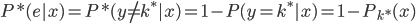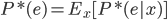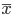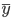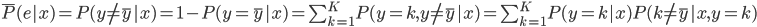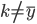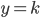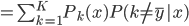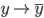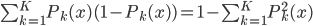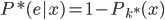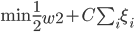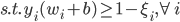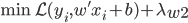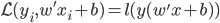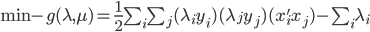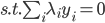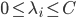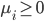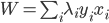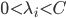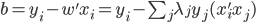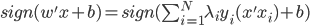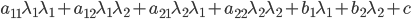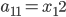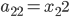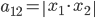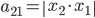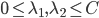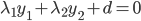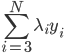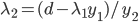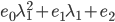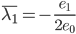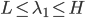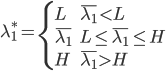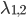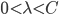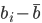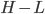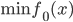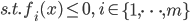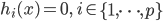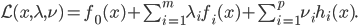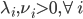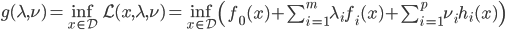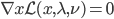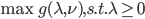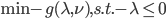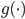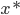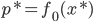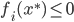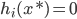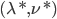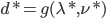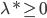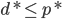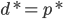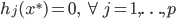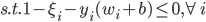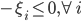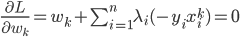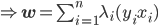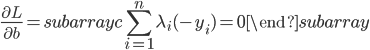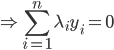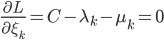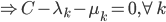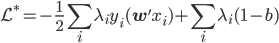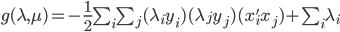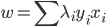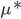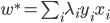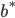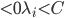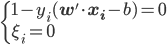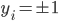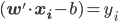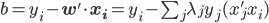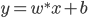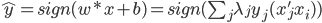分析是种职业病,融贯在每一分血液里,每一分骨髓里...去参加个Qcon看看人家的创意网站,然后心里各种痒痒,拉着思喆哥、堰平兄饭局讨论实现的原理也就罢了,最近只要一出门就习惯性的开始思考某些稍微“违背常理”或者“略显聪明”的现象...
比如这次去西安,在去的航班上,就开始思考起来了“航空公司的数据挖掘”....
-------------------回忆的分割线-------------
有些事情纯属职业病。这次上海飞西安坐的是南航的航班,一路折腾到飞机上就已经疲惫不已了,直接睡过去。
后面的一切毫无波折,如果不是临下飞机十几分钟的一段对话,我估计会对这段航行毫无记忆。只是突然间空姐的一句问候,"您是***女士么(我的本名)",让我第一反应是我不是你们的金银卡啊,这也开始问候了?...然后笑意盈盈的递给我一张会员申请表。"您虽然还不是我们的会员,但是您是我们的潜在会员。所以请您加入我们南航明珠俱乐部"...
我第一反应是,"潜在会员"这个是怎么分析出来的?目测我大概有一年的时间没有飞过南航(在过去的半年时间我似乎都完全没有飞过),难道他们有个"沉睡用户苏醒监测"?要不就是,正巧这次我累计乘坐南航的次数达到了他们分析的阈值(比如10次)?要不就是,每次坐南航我都累积东航,让他们终于忍无可忍了...还是说,他们真有一个customer life value model,算出来我对他们的潜在价值了?
蛮有意思的是,我曾经有段时间周周飞南航,他们却从来对我爱理不理,所以我猜测他们的模型里面对于"reactivated"的顾客有个很高的权重。
到最后,南航猜的准吗?准,有可能是我确实在东航还有一些里程可以挥霍。不准,则是我现在飞行大都是私人旅行了,基本不可能象以前做咨询时候出差那般频率了,所以我的潜在价值肯定没有模型上估计出来的高。如果这个模型进一步分析"公务旅行"还是"私人旅行",怕是效果会更好吧。不知道能不能通过机票代理来区分这两类客源...所以,准,却有点晚了。
当然对于垄断国企来说,这个CRM并不是那么重要,反正利润会一直在那里,国内的常客计划也发展不起来。只是感慨一下,这样的分析要是想做好,绝对离不开自己对于这项服务的亲身体验。只有飞的多了,才知道常客计划的最大引力和最关键时点。而后的分析,才会水到渠成吧?
职业病发作完毕...