先后看到zhiqiang和思喆大哥都在用「多说」了,就跟风复制到落园来了。
目前属于测试中...略略遗憾的发现原来的评论模板被覆盖了,桑心。其他貌似还正常。
本文开始测试嗯。
第九章 可加模型、树模型相关方法
大家都知道线性模型是最简单好用的,但是往往现实中很多效应都是非线性的。前面举过一个学历的例子,再抄一下:
一方面,学历是你受教育的体现,也就是在取得学历的过程中完成了一定程度的知识积累。当然一定程度的学校录取证实了你一定程度的才智,但是也不是只有天才没有汗水就可以毕业的。更有意思的是,知识的积累往往是厚积而薄发,或者说是个非线性的...这也是为什么在衡量劳动者劳动价值的时候会放入受教育年限和其二次方的一个缘故(至少我是这么理解那个著名的xx公式中的二次方项的)。
也就是说,在线性模型中,我们最简单的方法就是利用多项式拟合非线性,不是有个著名的魏尔斯特拉斯(Weierstrass)逼近定理么?闭区间上的连续函数可用多项式级数一致逼近。
这个定理貌似在数分、实变、复变、泛函都有证明(如果我没记错名字的话)...泰勒(局部展开)也是一种局部使用多项式逼近的思路。不过 人类的智慧显然是无穷的,自然有了应对各种各样情况的“万能药”和“特效药”,任君对症下药什么的。
这一节主要是讲generalized additive models,即广义可加模型。广义可加模型假设的是:各个自变量之间不相关,即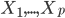 可以被拆分开(虽然书上是用期望定义为
可以被拆分开(虽然书上是用期望定义为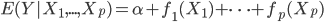 ,但是我觉得加入一些人为认定的交叉项再扩展开是没有问题的~)。数学表达式就是:
,但是我觉得加入一些人为认定的交叉项再扩展开是没有问题的~)。数学表达式就是:
(1) 定义: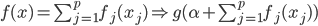 ,其中
,其中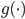 是已知的,而
是已知的,而 和
和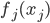 是需要估计的。可见,如果只是从我们线性模型的
是需要估计的。可见,如果只是从我们线性模型的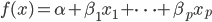 进化到
进化到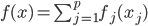 ,那么我们是放松了对于
,那么我们是放松了对于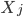 是线性的要求,可以对每个自变量进行非线性回归,但y和这些之间依旧是线性关系;如果进一步放松,那么就可以引入新的非线性函数,那么y和那一堆之外还可以再套一层非线性函数。不过这里就要求给定一个g了,常用的就是那些指数函数对数函数等。
是线性的要求,可以对每个自变量进行非线性回归,但y和这些之间依旧是线性关系;如果进一步放松,那么就可以引入新的非线性函数,那么y和那一堆之外还可以再套一层非线性函数。不过这里就要求给定一个g了,常用的就是那些指数函数对数函数等。
不过这里我们还要要求有一些比较优良的性质,首当其中就是可逆...(对于连续函数来说,可逆必定单调...因为可逆 一一映射,又是连续的函数,不单调这就没法玩了呀!)好在我们一般就用一些比较简单的exp和log...常用的有:
一一映射,又是连续的函数,不单调这就没法玩了呀!)好在我们一般就用一些比较简单的exp和log...常用的有: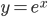 ,
,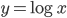 ,
,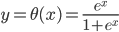 ,这样
,这样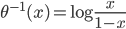 ...其中最后一个就是我们常用的logit regression。这样我们就可以定义“广义可加的logit模型”:
...其中最后一个就是我们常用的logit regression。这样我们就可以定义“广义可加的logit模型”: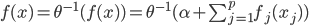 。
。
(2) 算法。还是一样的,有了大致的idea我们还得有好用的算法。下面介绍一种比较一般性的方法。
数据集依旧记作: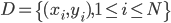 ,然后我们使用OLS准则:
,然后我们使用OLS准则: 。然后我们有迭代算法:即已知
。然后我们有迭代算法:即已知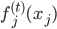 ,如何迭代到t+1?
,如何迭代到t+1?
p个小步:每一次我们都是用给定的其他,其中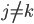 ,求得
,求得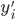 ,来最小化计算第k个变量的系数
,来最小化计算第k个变量的系数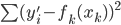 ,求的
,求的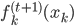 。这样的方法称为一维平滑值(one dimension smoother)。而在这个过程中,需要利用B-splines来求。所以“其实本来该模型的卖点是非参数,但是最后做一维平滑的时候还要利用参数化的B-splines...”,所以有点打折扣的感觉对不?
。这样的方法称为一维平滑值(one dimension smoother)。而在这个过程中,需要利用B-splines来求。所以“其实本来该模型的卖点是非参数,但是最后做一维平滑的时候还要利用参数化的B-splines...”,所以有点打折扣的感觉对不?
每p个小步构成一个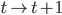 的大步。如果最后是用B-splines来拟合,那么其实一开始就可以代入各种参数一次性完成参数化计算。
的大步。如果最后是用B-splines来拟合,那么其实一开始就可以代入各种参数一次性完成参数化计算。
唯一值得考量的就是,这个迭代可能是局部最优化而不是全局最优化,有点取决于起始值的味道...我有点怀疑这个起始函数要怎么给...
(3) Na?ve Bayes Assumption(朴素贝叶斯假定)
有个有趣的结论:在Na?ve Bayes 假定下,分类器一定是可加模型。
直觉上讲,Na?ve Bayes假定其实也是假定分量独立: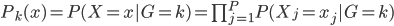 。
。
这样就很容易推导这个结论了:我们有后验概率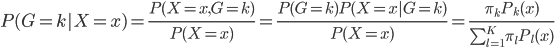 。取个对数,我们有
。取个对数,我们有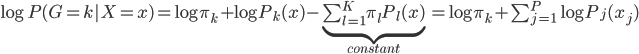 ,所以就成了可加模型的形式。这样,Na?ve Bayes 假定比可加模型的假定就更弱一点。关于这点,我又去搜了一下,呃,找到了一点有关的信息,抄如下:
,所以就成了可加模型的形式。这样,Na?ve Bayes 假定比可加模型的假定就更弱一点。关于这点,我又去搜了一下,呃,找到了一点有关的信息,抄如下:
简单的说,就是“判别式模型与生成式模型”的问题。如果我们使用参数方法逼近联合分布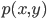 ,那么就是生成式模型(generative models);相对的,如果我们直接对条件密度p(y|x)建模而不对p(x)进行任何假定,那么就是判别式模型(Discriminative methods)。我们常见的就是LDA和线性logit模型、朴素贝叶斯和广义可加模型。在一些已知如高斯分布的情况下,我们发现LDA优于logit并且有更小的方差,但是生成式模型的问题就是他的参数假定不满足...所以估计可能是有偏的。所以现实中,我们需要在无偏性和方差之间做一个trade off。关于这里的总结我搜到一篇:Discriminative vs Informative Learning - Stanford University,习惯中文的可以参考一下这个。其实这里看看这些概念和思想之争也挺好玩的,以前完全没有从这个角度看过回归模型...可见计量经济学关心的完全不是这些东西。我现在完全没概念我在machine learning这个深潭里面到底涉足多深了,但是可以明显的感觉统计学习的一些思维已经开始影响我的思维方式了...需要再继续融会贯通一下。
,那么就是生成式模型(generative models);相对的,如果我们直接对条件密度p(y|x)建模而不对p(x)进行任何假定,那么就是判别式模型(Discriminative methods)。我们常见的就是LDA和线性logit模型、朴素贝叶斯和广义可加模型。在一些已知如高斯分布的情况下,我们发现LDA优于logit并且有更小的方差,但是生成式模型的问题就是他的参数假定不满足...所以估计可能是有偏的。所以现实中,我们需要在无偏性和方差之间做一个trade off。关于这里的总结我搜到一篇:Discriminative vs Informative Learning - Stanford University,习惯中文的可以参考一下这个。其实这里看看这些概念和思想之争也挺好玩的,以前完全没有从这个角度看过回归模型...可见计量经济学关心的完全不是这些东西。我现在完全没概念我在machine learning这个深潭里面到底涉足多深了,但是可以明显的感觉统计学习的一些思维已经开始影响我的思维方式了...需要再继续融会贯通一下。
(1) 树的一般概念:见过二叉树么?差不多的样子可以有多个叉叉...自行脑补一下分形去吧。
(2) 回归树(regression tree)
还是数据集,然后我们可以根据不同的门限来分类,比如x<;1分在左边枝子上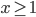 放在右边枝子上。然后在下一层继续分叉分叉...一层又一层。感觉当初发明树模型的孩子一定很喜欢生物学尤其是植物学吧!有没有类似于顶端优势的定理呢?嘻嘻,可以叫做歪脖子树定理嘛!
放在右边枝子上。然后在下一层继续分叉分叉...一层又一层。感觉当初发明树模型的孩子一定很喜欢生物学尤其是植物学吧!有没有类似于顶端优势的定理呢?嘻嘻,可以叫做歪脖子树定理嘛!
 (八卦来源)
(八卦来源)
对于一颗树T,我们采用如下记号:
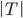 :叶子的总数
:叶子的总数
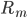 :
: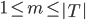 ,某个叶子或者根节点。
,某个叶子或者根节点。
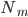 :叶子节点 中的样本数。
:叶子节点 中的样本数。
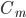 :
: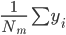 ,这个点y的平均值。
,这个点y的平均值。
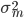 :
: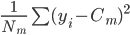 ,每个
,每个
中的均方误差(方差)。
这样一颗树的质量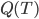 就可以定义为
就可以定义为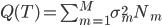 。这样给定一棵树,有了一个函数
。这样给定一棵树,有了一个函数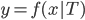 ,然后就可以预测了。
,然后就可以预测了。
树的生长:这就是叶子和层次的选择,显然我们一共有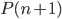 中选择。需要从中选出最好的
中选择。需要从中选出最好的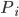 和
和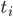 。当生长不动的时候,停止。而长得太大的时候,就是过拟合的问题。所以我们需要剪枝。
。当生长不动的时候,停止。而长得太大的时候,就是过拟合的问题。所以我们需要剪枝。
树的剪枝:准则需要变,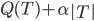 ,即加入一个惩罚项,然后就可以使用cross-validation或者bootstrap了。
,即加入一个惩罚项,然后就可以使用cross-validation或者bootstrap了。
(3) 分类树
同样的,只是我们需要定义新的准则,类似于0-1准则。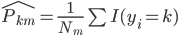 ,也就是节点中属于第k类的比例,所以
,也就是节点中属于第k类的比例,所以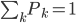 。
。
这样我们就有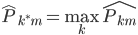 ,即主导类别占据该节点。
,即主导类别占据该节点。
定义1:我们的预测误差就是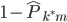 ,就可以定义
,就可以定义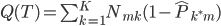 。
。
定义2:熵。我们定义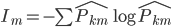 ,这样就可以定义
,这样就可以定义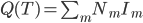 。
。
定义3: 基尼准则(Gini),定义函数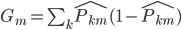 ,然后
,然后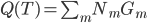 。
。
有了准则之后,我们就可以生长、剪枝和预测了。
为啥我觉得这就是决策树呢?喵了个咪的,就是一个质量定义问题嘛。回归和分类器之鸿沟一直延续呀,无论是线性模型还是树模型...
前一篇偏流水账,就不浪费大家的时间了。
2012的收获大致有:
1. 更多的交流,结识更多新朋友。收益于第一份咨询工作,我学会了如何更好地沟通、让事情更平滑的move on。换位思考是最最宝贵的经验,business最重要的就是和人打交道。受益于新的在eBay的工作,我学会了如何更坚实的结合一个business idea和model,也体会到分析结果对于真实商业行为的影响。每次看到managers的summary sides都让我由衷感慨一下。受益于各种会议沙龙活动,结识了很多不同领域的朋友(就不一一列出了,埋藏感激于心底)。真的,Life is better when shared! 好享受这种互通有无的过程,真诚的沟通一直让人感动。人生何处不相逢,希望有更多的机会可以和这些好朋友们学习。
2. 知识的增长。skill层面,在诸多大牛的熏陶下下,耳濡目染的用R鼓捣起来文本分析,很有趣;从老板和同事那里学了很多SQL技巧;连续七天攻克了SAS。课程方面,跟下来了coursera的model thinking和复旦的elements of statistical learning。另参观了若干博物馆,文化知识稍稍增长。
3. 读书。 抄一下豆瓣的list,几本印象深刻的书:elements of statistical learning(cos论坛大牛推荐),rework(yihui推荐), presentation zen(impress.js推荐), 什么是数学+高观点下的初等数学(周涛推荐),浪潮之巅+数学之美(一位做sales的朋友推荐),the little sas book, 怪诞行为经济学(一位老友推荐),中国哲学史(大学存货),另附若干R书籍。小说方面有印象的就是三体了,三个不眠不休的整日搞定(辞职之后进藏之前),再就是暑假恶补了王家卫的电影(邻居推荐)。
没了...2012还算丰盛,希望2013节奏再快再舒适一点,和大家一起成长!
-------------------
去年的总结在这里:time-to-change/,硕士毕业时候的总结在这里: a-brief-summary-of-my-master-year/。今年的主题依旧是:chasing my dream。
以下为某天早晨打车来上班的十几分钟路上乱想到的,海涵。
---------------------------
有的时候我都觉得自己被microeconomics毒害太深...整个思维体系全是架构在其之上的,不管是最简单的供求和弹性之类,还是更强调互动的game theory...相比而言,我的macroeconomics直觉就差了很多了,除了能偶尔侃侃税制、社保和房市,我实在是不知道还有什么好关注的宏观经济动向。
大家都在一窝蜂的挤入金融市场,各种各样纷杂缭乱的手段都有,真是集各学科智慧于大成。所有人都在预测、预测。其实预测和信息这东西,只有在“你先于市场知道”的时候才有价值,你知道别人也知道,这信息就已经富含在预期里面了,价格就已经包含了这部分预期。前两天看到新华社一常驻纽约和纳斯达克证交所记者说,美股其实比较好预测——是的,几乎有什么新闻就有什么相应的反应。这也就是说对于大家都知道的信息,价格的反应是很有规律可循的。
看了那么多模型,我还是觉得金融的本质是博弈——你需要比别人先知先觉,不管是以什么方式。更有资本的,就是去找体制的漏洞,所以有索罗斯搅乱英国和香港汇率市场(商务印书馆的索罗斯三部曲不妨一读:金融炼金术、开放社会: 改革全球资本主义、索罗斯论全球化);或者引领市场,比如巴菲特对于投资的带动(我印象最深的就是比亚迪的案例了)。神话之所以成为神话,就是他们是领先而且不可复制的。机不可失,失不再来。
说了这么多金融市场,只是想多少建立一点概念:这个「机制」是一个多么神奇而好玩的东西。玩过魔兽或者三国杀的朋友们或许都对游戏平衡设计印象颇深,这是多么活生生的机制设计案例呀。扯回到市场营销嗯...
营销其实无非就是一个「投入、产出」的过程。你有一堆起始营销资源,然后投放到各个渠道,然后衡量一下各个渠道的投入产出比(ROI),然后根据产出决定下一期怎么优化后继续投入...这说起来和其他投资并无二致之处。对于不同层次的营销人员来说,区别可能是营销资源的量不同、资源的形式不同(钱,时间,精力,实体物质等),再就是可选的营销渠道不同、对于每个渠道的掌控能力和信息不同、ROI的衡量方式不同。这么再去看各种形式的营销,大致也就是在这个框架之内,没什么太神秘的。只是这个环节比较多分工比较细,大家在不同环节上努力罢了。
说个最常见的营销资源投放案例吧:我有一堆优惠券,怎么发放?(瞬间想起小时候去KFC门口,然后一个和蔼可亲的肯德基爷爷塞到我手中一把KFC优惠券的场景了...拿到券的瞬间就不会在KFC还是麦当劳这个问题上犹豫了)优惠券是个很神奇的东西,其实就是变相的价格歧视——有路子找到优惠券的可以享受更低廉的价格,而没有路子的就只能原价付款了。所以我们要找出来的目标群体无非就是:价格敏感的、在买与不买之间徘徊不绝的。这样才能发挥优惠券的最大功效嘛——你给那些一天三顿非KFC不吃的人发券有什么意义?他们本来也要来吃的。找到这样的合适群体,就是建立"参与约束";而使得合适群体做出你想要的行为,就是"激励相容"了。一个机制设计的成功,无非就是满足如上两点。
所以我现在在看到手里经过的分析任务之时,总会不自觉的去开一分钟小差考量一下,这东西满足"激励相容"么?然后默默的继续工作...同样的,经常会在收到各种促销短信邮件的时候,考察一下店家是不是足够聪明...如果有明显的套利机会(过度相容了),就会立马实行:比如某品牌的药妆,我每次都是在其淘宝旗舰店打5折的时候买一年的量囤着,然后等明年打折的时候再去买。类似的例子还有一些,基本就是在我的时间耐心与价格敏感之间寻的一个平衡点,然后就可以优化一下消费流。所以我一直觉得我是一个很符合"贴现效用最大化"的理性消费者...
还是说一个更让大家熟悉一点的参与约束和激励相容例子吧。我们一直期冀"我劝天公重抖擞,不拘一格降人才",但是又在求职和招人的时候不自觉的考量人家的学历。学历到底有多少含金量?学历不等于能力?
一方面,学历是你受教育的体现,也就是在取得学历的过程中完成了一定程度的知识积累。当然一定程度的学校录取证实了你一定程度的才智,但是也不是只有天才没有汗水就可以毕业的。更有意思的是,知识的积累往往是厚积而薄发,或者说是个非线性的...这也是为什么在衡量劳动者劳动价值的时候会放入受教育年限和其二次方的一个缘故(至少我是这么理解那个著名的xx公式中的二次方项的)。
另一方面,这也是一个信号:如果你是能力低下的人,那么完成学位需要付出的痛苦会有很多,这样就使得只有能力强一点的人才会选择更高的学历。因此,学历成为了能力的一个信号。
但问题也来了:这个信号区分度如何?显然是比较粗的。再者,这个机制的顺畅运行显然不仅仅是录取阶段的公平考核及没有经济负担能力等现实约束,而且更多是学习过程的努力付出。我隐约觉得中国的研究生扩招就是把两个重要环节的标准都放低了,所以这个信号的作用越来越差,噪音越来越多。研究生找工作难不单单是一个经济大形势和供给增加导致失衡的问题。
医保体制可以研究的就更多了,比如挂号费到底应该怎么设置才合理,医生的劳动价值怎么可以被体现出来...这都是微观经济学基础上的机制设计研究的问题。当然经济学也在脚踏实地的解决更多现实的问题。我一直觉得经济学给出的是抽茧剥丝分析问题的框架,而不像某些经济学家一天到晚只会在媒体上骇人听闻。我现在看到某些人的微博夸夸其谈的言论真是一阵胃里泛酸。
今年夏天的时候,刚刚开始被SQL虐,写了一篇很无知且更多是吐槽意味的blog post: 关于R的若干SQL等价问题。当时被若干朋友批评,我还浑然不觉个中精要。现在用Teradata也有半年多的时间了,越来越习惯了SQL的表述方式,也越来越体会到Teradata作为一个强大的数据仓库系统,是有多么的伟大...这感觉,就是只玩过几个G数据的乡下人进城,猛然看到各路英雄都是动辄几个T的数据,只能暂时以原来落后的思维方式、勉强挥舞着新型工具...好在个性不是特别愚钝,终究还是可以慢慢地领悟到T级数据的奥妙之处,终究用着新武器也越来越顺手了。
这一段时间,也充分证明了我是master in economics而绝对不是 in cs。数据库系统的原理终究学的不深——我哪儿知道MySQL的SQL和Teradata的SQL差了那么多呀...后来慢慢的去听同事传授TD使用经验,慢慢的去看老板传过来的代码,慢慢的一次次处理掉 no more spool space的错误和一次次接到SQL语句效率低强制退出的警告信之后,才逐渐地越来越了解TD的原理和脾气。工欲善其事,必先利其器,这些都是沉重的学费。
所以各位如果没有看过那篇「无知者无畏」状post的,就不要看了。直接接受我诚挚的道歉然后看下文吧。Teradata下简称TD。绝非专业知识,只是个人有限的了解,不对之处请及时批评。
有次跟同事聊,问他们为什么不在本机上装个TD测试用...然后被狠狠鄙视了一番——TD没有单机版!天生就是架在云上的。这东西还真是个原生的分布式数据仓库。
TD和oracle的关系也比较简单:一个是数据仓库,一个是数据库,功能设计什么的压根就不一样。这么说吧,oracle支撑的是ebay的网站运行,所以必然涉及大量的查询、插入、删除等请求。更麻烦的是,以ebay的访问量,这些请求都是同时过来的,这就要求系统并发性要好一点(专业人士可以绕道了,我只是浅薄的知道一点东西...)。体验过12306买火车票排队的大家,想必都知道这个系统并发起来的厉害。ebay若是也来个排队,消费者还不疯掉...
为了应对这样的任务,oracle的数据库设计自然是要按那「三大范式」来。这个就不多说了,再说就暴露了...
TD则是把oracle的数据定期地导出来存着,所以除了简单的复制数据之外,还要对数据进行一定程度的清理和整理,并不完全是最最原始的数据。然后到了食物链上端数据分析师手里,面对的数据很多都是已经弄的很整齐的了。说是食物链上端,只是因为这大概是分工中需要用到原始数据的最后一拨人,且这拨人用到的最多的就是查询(甚至是整表查询)和计算,所以我们写SQL的时候更多是考虑到这些需求,利用TD在这方面的性能优势——我已经很少在SAS或者R里面进行数据整理的工作了,性能跟TD完全不是一个量级的。
下面是TD使用的若干经验,不过这东西只有自己碰壁了才知道个中真滋味,我就是缩短一下解决问题的进程,不用太折腾到处搜来搜去。
No more spool space。当你的SQL没有语法错误,那么最常见的运行不下去的情况就是 no more spool space了,这大概是每个用TD的不管新鸟老鸟都会经历的痛苦历程。这个错误就像R里面报"cannot allocate a vector of size ***",或者你玩游戏正high的时候系统告诉你内存不足。解决的思路就是"空间换时间",就是看你具体怎么换了。
1. 多表join查询的时候,就要看这些表是怎么merge的——TD会去算是一大一小join,还是两个大表join。前者TD会复制小表到每个大表的"节点"上(大表肯定要分块存起来嘛),所以可以事先加collect statistics on *** column ***。后者就要费点脑子了,争取两个表的排序(PI)一致,这样TD join的时候就不需要对两个表都重新排列了是不是(merge join)?每一次重排都会占掉大量的临时空间呢。再者,查询结果储存到另外的永久或者临时表里面,就要注意primary index(简称PI)的选择,不要让TD再把查询结果重排...
2. 除了看primary index,有时候还要去注意partition by。有些已经建好的超级长的表需要去看是怎么真正"分块"存储的。对于partition by 的字段设定一个where条件,会让TD很快的知道你要查询和join的是哪些部分,大大缩短范围。一般说来,最常见的partition by就是时间了,缩短一个时间范围也不失为良策嘛。
3. 擅用cast()可以避免很多跟数据类型有关的错误,这个就不赘述了。
4. No space on ***说明没有永久表的存储空间了,这个就得去删过于古老的表和去要新的空间了。
5. 每段SQL不要太长,join不宜太多。熟悉TD的脾气之后,就张弛有度了,擅用临时表。
6. 多用group by少用distinct。
7. 最后终极野蛮办法,如果实在是没法两个大表join又没有partition by的话...手动按PI拆其中某个表吧。
----例行碎碎念----
那些在LinkedIn上endorse我R的朋友们,我真心感觉承受不起呀!至今依旧觉得我的R很烂,代码只停留在"可运行"的水平,效率大都很糟糕,基本就是折磨CPU的...哎,非科班出身终究是有莫大的差距呀。