这篇文章基本上就是我被Teradata折腾的辛酸血泪史...TD有TD的长处,但是还不足以应付所有的分析任务。所以不得不面对各种把数据折腾出来折腾出去的任务...(好吧我还没开始被Hadoop虐呢,到时候务必又是一番惨死景象)。
Teradata文本导入导出
Teradata SQL Assistance直接输入输出
这个适用于本地安装了Teradata SQL Assistance的windows系统,然后我个人的建议是不要下载多于10w行的数据,要不会很烦。也不要上传多于1w行的数据,要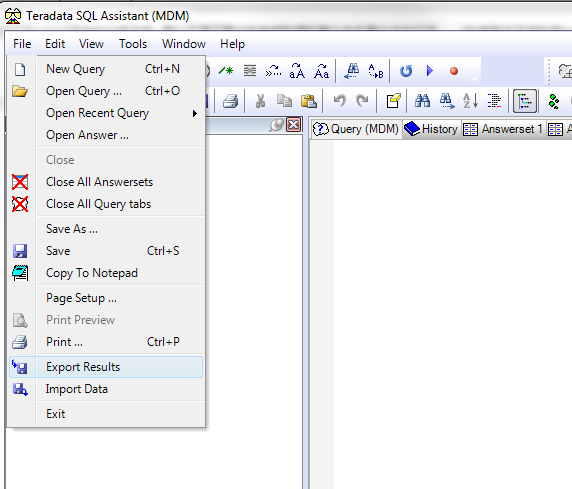 不会更烦。
不会更烦。
导出文本(csv)比较简单,直接选定 File->Export Result就可以了,然后任何运行SQL的输出都会输出到文本文件里面,主要就是 SELECT 出来的结果。
这个时候,TD会有提示"Future results will be Exported to a file"。

类似的,可以选择File->Import Data来读入数据,这个时候会让你选择一个现成的文本(csv)文件,然后告诉TD怎么读就可以了。
举个例子,比如我们有一些邮政编码和城市名称的数据,格式如下:
County,Town,ZIP_CODE
Bronx,Bronx,10451
Bronx,Bronx,10452
Bronx,Bronx,10453
Bronx,Bronx,10454
Bronx,Bronx,10455
Bronx,Bronx,10456
Bronx,Bronx,10457
Bronx,Bronx,10458
Bronx,Bronx,10459
Bronx,Bronx,10460
Bronx,Bronx,10461
那么相应的code就可以写成:
CREATE MULTISET TABLE liyun_NY_DA_ZIP ( county CHAR(20) ,town CHAR(20) ,ZIP_CODE CHAR(5) ) Insert into liyun_NY_DA_ZIP values (?,?,?); /* import data from csv */
Teradata的FastExport
这个目前还只在linux下试验成功过...
一段代码长成这个样子:
.logtable p_r_test_t.exp_log; .logon mozart/username,password; .begin export sessions 20; .export outfile usa_all.txt mode record format text; select cast(cast(x.byr_id as decimal(18) format 'ZZZZZZZZZZZZZZZZ9') as CHAR(18)), ',' (char(1)), cast(cast(x.recency as decimal(4) format 'ZZZ9') as CHAR(4)), ',' (char(1)), cast(cast(x.frequency as decimal(4) format 'ZZZ9') as CHAR(4)), ',' (char(1)), cast(cast(x.monetary as decimal(8) format 'ZZZZZZZ9') as CHAR(8)) from p_r_test_t.dw_mbl_rfm_all x; .end export; .logoff;
然后存成一个脚本文件,比如your_fast_export_script.txt, 之后就可以直接在Shell里面调用了。
fexp < your_fast_export_script.txt
需要注意的是如果报各种稀奇古怪的错误,可能是编码尤其是换行符的问题...
FastLoad还米有试过。
Teradata导入导出到R里面
Teradata导出数据到R里面
如果想省心,那么就直接用TeradataR这个包。然后可能需要安装一下TD的ODBC driver: http://downloads.teradata.com/download/connectivity/odbc-driver/windows。
简单的配置之后,就可以直接调用TeradataR了。
library(teradataR)
TDuid <- "xxx"
TDpwd <- "xxx"
connect_mozart = tdConnect(dsn = "xxxxx", uid=TDuid, pwd=TDpwd, database = "xxx")
#download the table and run summary locally
data_open <- tdQuery(" select * from xxxx order by 1,2,3,4,5,6;")
tdClose()
但是可惜的是这个包里面不提供导入回TD,只能去调用RODBC的原始命令。
R里面数据导入Teradata
#upload data connect_mozart = odbcConnect(dsn = "xxx", uid=TDuid, pwd=TDpwd) summary(aim_data) sqlQuery(connect_mozart, "drop table xxxx;") #如果已经有这个表了 sqlSave(connect_mozart, aim_data, tablename="xxxx",rownames=F,fast=T) odbcClose(connect_mozart)
这样就可以了。不过速度真心不怎么快(fast=F)会更慢。不建议使用大于1k行的R data.frame。
Teradata导入导出到SAS里面
Teradata导出数据到SAS里面
鉴于SAS可以直接用FastExport和FastLoad,这个速度就相当可观了。
proc sql noprint; Connect To Teradata (user=&user password="&pwd" database=access_views tdpid=mozart mode=teradata); create table xxx.xxxx as select * from connection to Teradata ( select * from Xxxx.xxxx order by 1,2,3,4,5,6; );
SAS里面数据导入Teradata
类似的,可以很快的把数据从SAS导入TD。
proc sql noprint; Connect To Teradata (user=&user password="&pwd" database=access_views tdpid=vivaldi mode=teradata); execute (drop table xxxxx.xxxx) by teradata; execute ( create table xxxxx.xxxx ( USER_ID DECIMAL(18,0), CMC_ID INTEGER, CMC_START_DT DATE FORMAT 'YYYY/MM/DD', SEGM_GROUP VARCHAR(255) CHARACTER SET UNICODE NOT CASESPECIFIC, CHANNEL VARCHAR(5) CHARACTER SET UNICODE NOT CASESPECIFIC ) PRIMARY INDEX(USER_ID, cmc_id) ) by teradata; Disconnect From Teradata; quit; proc append base=vivaldi.xxxx(fastload = yes fbufsize = 32000) data=mz_sas.xxxx force; run;
由于调用了fastexport和fastload,这速度明显改善,实测2G数据大概在5分钟左右,蛮快的了(6M/s)呢。
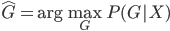
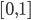
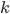
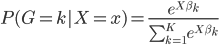
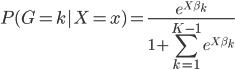
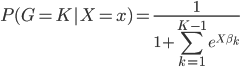
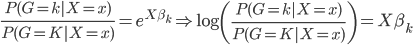
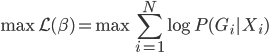
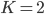
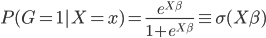
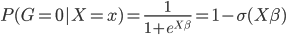

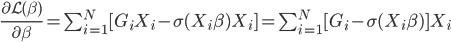
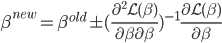
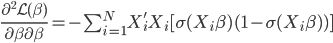
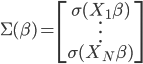
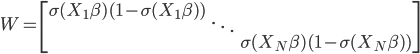
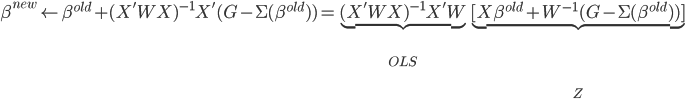
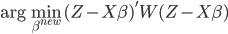
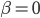
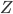
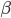
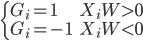
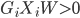
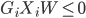
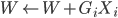
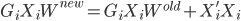
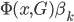
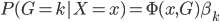
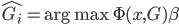
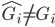
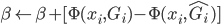
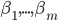
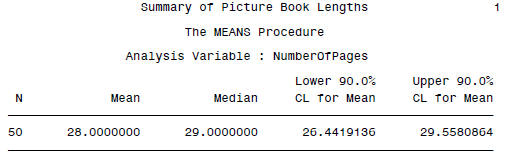
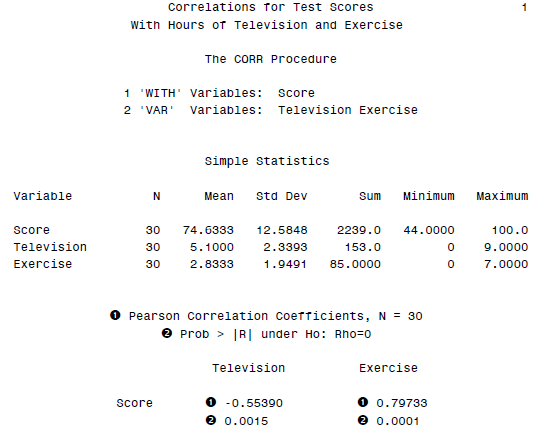
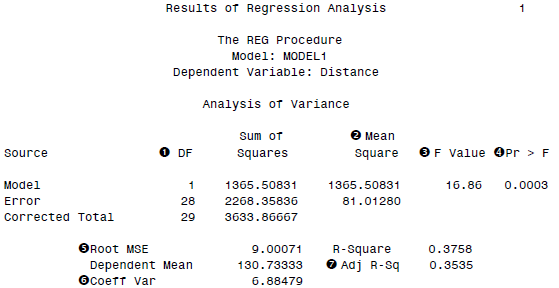

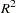 to the OUTEST= data set
to the OUTEST= data set