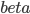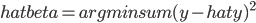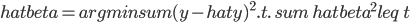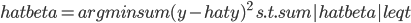前几天放出来的那个R的展示中,有说到其实学R的过程更多的就是熟悉各种函数的过程(学习统计模型不在此列...我个人还是倾向于不要借助软件来学习理论知识,虽然可以直接看codes...笔和纸上的推导还是不可或缺的基本功),然后各种基础函数熟悉了之后很多被打包好的函数就是缩短代码长度的利器了。
excel里面有神奇的“数据透视表(pivot table)”,其实很多时候真的已经很神奇了....不过我还是喜欢R,喜欢R直接输出csv或者xlsx的简洁。揉数据呢(学名貌似叫数据整理),我也还是喜欢写出来代码的形式,而不是直接向excel那样面对结果。只是感觉更加不容易出错吧。
揉数据,顾名思义,就是在原有的数据格式基础上,变化出来其他的形式。比如,长长的时间序列变成宽一点的~当然这个可以简单的借助reshape()函数了。可惜我还是不死心,想找一个更好用的,于是就自然而然的看到了reshape2这个包。
这个包里面函数精华在melt()和*cast()。说实话melt()耗了我一段时间来理解,尤其是为什么需要先melt再cast...后来发现这个步骤简直是无敌啊,什么样的形状都变得更加容易揉了,大赞。
warm-up完毕,还是回到正题吧,怎么用reshape2揉数据呢?虽然reshape2支持array, list和data.frame,但是我一般还是习惯于用data.frame,所以还是说说这东西怎么揉吧。揉数据的第一步就是调用melt()函数,不用担心你的input是什么格式,这个函数array, list和data.frame通吃。然后,要告诉他哪些变量是(唯一)识别一个个体的,这句话是什么意思呢?我们先看melt()的参数:
melt(data, id.vars, measure.vars,
variable.name = "variable", ..., na.rm = FALSE,
value.name = "value")
其中id.vars可以指定一系列变量,然后measure.vars就可以留空了,这样生成的新数据会保留id.vars的所有列,然后增加两个新列:variable和value,一个存储变量的名称一个存储变量值。这样就相当于面板数据的长格式了。直接拷一个作者给出的例子:
原数据:
head(airquality)
ozone solar.r wind temp month day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
6 28 NA 14.9 66 5 6
dim(airquality)
[1] 153 6
然后我们将month和day作为识别个体记录的变量,调用melt(airquality, id=c("month", "day")):
head(melt(airquality, id=c("month", "day")))
month day variable value
1 5 1 ozone 41
2 5 2 ozone 36
3 5 3 ozone 12
4 5 4 ozone 18
5 5 5 ozone NA
6 5 6 ozone 28
dim(melt(airquality, id=c("month", "day")))
[1] 612 4
嗯,这样数据就变长了~然后,就可以随意的cast了...dcast()会给出宽格式的数据,比如我们想把day作为唯一的识别,那么:
names(airquality) <- tolower(names(airquality))
aqm <- melt(airquality, id=c("month", "day"), na.rm=TRUE)
head(dcast(aqm, day ~ variable+month))
day ozone_5 ozone_6 ozone_7 ozone_8 ozone_9 solar.r_5 solar.r_6 solar.r_7 solar.r_8 solar.r_9 wind_5 wind_6 wind_7 wind_8 wind_9 temp_5 temp_6
1 1 41 NA 135 39 96 190 286 269 83 167 7.4 8.6 4.1 6.9 6.9 67 78
2 2 36 NA 49 9 78 118 287 248 24 197 8.0 9.7 9.2 13.8 5.1 72 74
3 3 12 NA 32 16 73 149 242 236 77 183 12.6 16.1 9.2 7.4 2.8 74 67
4 4 18 NA NA 78 91 313 186 101 NA 189 11.5 9.2 10.9 6.9 4.6 62 84
5 5 NA NA 64 35 47 NA 220 175 NA 95 14.3 8.6 4.6 7.4 7.4 56 85
6 6 28 NA 40 66 32 NA 264 314 NA 92 14.9 14.3 10.9 4.6 15.5 66 79
temp_7 temp_8 temp_9
1 84 81 91
2 85 81 92
3 81 82 93
4 84 86 93
5 83 85 87
6 83 87 84
或者对于每个月,求平均数:
head(dcast(aqm, month ~ variable, mean, margins = c("month", "variable")))
month ozone solar.r wind temp (all)
1 5 23.61538 181.2963 11.622581 65.54839 68.70696
2 6 29.44444 190.1667 10.266667 79.10000 87.38384
3 7 59.11538 216.4839 8.941935 83.90323 93.49748
4 8 59.96154 171.8571 8.793548 83.96774 79.71207
5 9 31.44828 167.4333 10.180000 76.90000 71.82689
6 (all) 42.12931 185.9315 9.957516 77.88235 80.05722
当然还有更强大的acast(),配合.函数:
library(plyr) # needed to access . function
acast(aqm, variable ~ month, mean, subset = .(variable == "ozone"))
5 6 7 8 9
ozone 23.61538 29.44444 59.11538 59.96154 31.44828
嗯,基本上数据就可以这么揉来揉去了...哈哈。怎么感觉有点像数据透视表捏?只是更加灵活,还可以自定义函数。
此外还有recast()可以一步到位,只是返回的是list;colsplit()可以分割变量名...函数不多,却精华的很啊。
--------------------
题外废话:我的小册子哎~只能这样零零碎碎的写一些了,事后再统一整理进去好了。不要鄙视...