好久没写关于经济学的文章了...今天看到两个搞matching的人拿到诺奖,瞬间想起当年和一个学心理学出身的童鞋一起搞的考虑到心理学因素的matching game...可惜最后没有时间完善,就放在那里当雏形了。我们的idea应该还是蛮有新意的呢~matching需要设计机制,然后用博弈来解,哎,很好玩的...
很多人都知道我是不搞时间序列分析的,尤其不喜欢基于时间序列的因果推断(格兰杰因果检验几乎是被我打入黑名单的一个词)。但这次为什么专门写这么一篇blog post呢?其实,我不反对时间序列作预测嘛~而google这篇paper,目的在于预测,又是latex排版的(搞不好还有sweave或者knitr的功劳),读起来赏心悦目的多。
这篇paper题目是:
Large-Scale Parallel Statistical Forecasting Computations in R
地址见:http://research.google.com/pubs/pub37483.html
亮点自然是:大数据计算、map reduce、时间序列分析、bootstrap (所以说google是一家让人尊敬的公司,http://t.cn/zlbAYJY这里总结了他将学术成果悄无声息的服务于大众的案例)。虽说大半夜的,但看到这个东西,再也睡不着了,索性写完一吐为快。(那次沙龙还说到来着,看吧,google早把这些好玩的东西都搞定了,只是不公开拿出来给大家用罢了~)
1. 并行算法
并行算法这里,主要是map reduce。他们的任务主要有:
- Facilitate parallelism of computations on up to thousands of machines without access to shared NFS filesystems(上千个节点的并行计算,无共享的NFS文件系统).
- Make distribution of code and required resources as seamless as possible for analysts to minimize code modifications required to enable parallelism.(无缝衔接各环节,减少分析师写并行算法工作量)
- No setup or pre-installation of R or specific libraries should be required on the machines in the cluster. A virtual machine for the workers should be created dynamically based on the global environment and available libraries of the caller(节点上无需事先安装R,虚拟机会自动按需构建).
- Return results of parallel computations in list form directly back to the calling interactive session, as with lapply in R.(lapply函数直接返回并行结果)
- Allow the parallel functions to be used recursively, so that MapReduce workers can in turn spawn additional MapReduces.(并行函数可以循环调用)
系统构架如下:
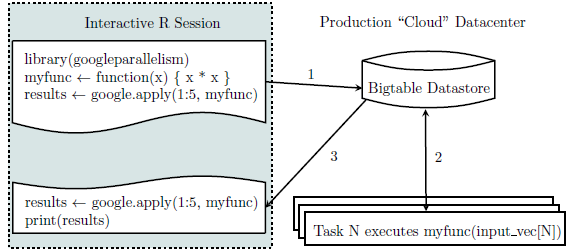
然后若干技术细节还包括,搞定R函数复制和计算的环境并行同步,搞定data.frame和list存储格式与在map函数中直接调用。搞定后,基本底层就搭建好了,剩下的就是调用R了。
2.时间序列预测
最典型的就是google trend的预测了...

这里他们直接用R包googleparallelism,然后希望用一些时序模型都尝试,做预测,然后取他们的均值(剔除上下总计20%)作为估计值以减少误差。示意图如下:
我只能说,果然是做机器学习的人啊,和random forest思路一致,弱的分类器结合起来,可能有意想不到的结果。同样的,每个模型都是多少有效的话,平均一下就更稳健啦,尤其是在大数据支撑下...
这样的平均之后已经无法直接推导方差和置信区间,所以他们采取了更依赖机器计算的bootstrap方法,直接强行算出来置信区间...喵的,我只能说谁让当年高斯那群天才整出来大数定律和中心极限定理呢?推不出来估量量方差不要紧嘛,直接重抽样模拟就好了...汗。
3.训练集
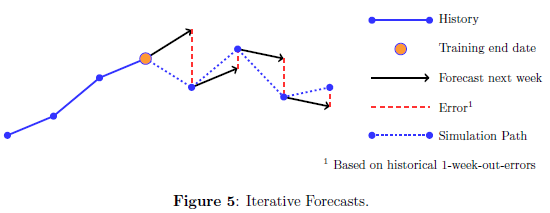
果然是做机器学习的人,接下来的思路就是直接一期期训练模拟呗。这个没啥说的了,见下图。
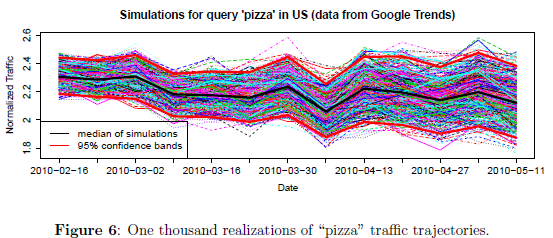
模拟出来的结果示意图:
至此,整个问题解决完毕。细节还请大家直接去看原文paper。我的几点感触吧:
- 1. 机器学习之所以在业界这么受欢迎,主要是其确实能够解决问题。迅速、有效,这个是其他方法比不上的。
- 2. 大数据、大规模计算,使得一些很简单的idea借助模拟和重抽样方法,大放异彩。
- 3. 预测,有时候不比因果推断次要。
- 4. 传统模型,需要适应大数据。
- 5. 说到底,理论体系还是有待完善的。希望这类方法是下一个微积分,可以先用,然后慢慢补充完相应理论体系。这样,我们才知道什么时候,需要勒贝格测度来取代原有牛顿积分。
总之,虽然无奈,但是有用之物必有有用的道理。期待对理论研究的冲击和激发。