这真的不是什么可以引以为豪的事情....我一直认为我是懂动态规划的,直到这两天重新看到动态规划的代码发现自己看不懂,然后恍然间意识到上次看懂都是7年前的事情了。google了一番搜到自己的blog真的是欲哭无泪,然后痛定思痛,觉得这次把它搞懂,重新写一篇笔记,这样万一若干年之后再回头看这个,至少保证这次的笔记有更多的含金量自己可以看懂。(更惭愧的是,高级宏观的时候天天在手动解动态规划,最多的就是无穷期动态规划,现在居然不怎么记得当年是怎么解的了...)
动态规划的用处还真多。很多例子都是斐波那次数列的,但是其实我感觉这样的例子并没有很明显的感觉。倒是今天看到一个文本排列的例子觉得很有意思,原来latex计算每行放多少词是用动态规划算的。想想word打字的时候也是不时会重排一下,所以大概也是在后面不停的算动态规划的最优结果吧。
动态规划的想法其实并不麻烦,大致就是一种以空间换时间的交换。今天耐着性子把youtube上mit公开课关于动态规划的两节看完了(19节和20节),顺便拿笔在旁边记了一堆笔记。然后找了两个例子用python练习了一番,又看了一下其他人的答案,开车回家的路上顺便又想了一下,这才觉得这次好像是想明白动态规划了。所以在这里记一下。
最短路径的动态规划解法
先来个简单的例子?路径问题好了。这个好像是最经典的动态规划例子了。我这里随便画了一个图(神器在此)。
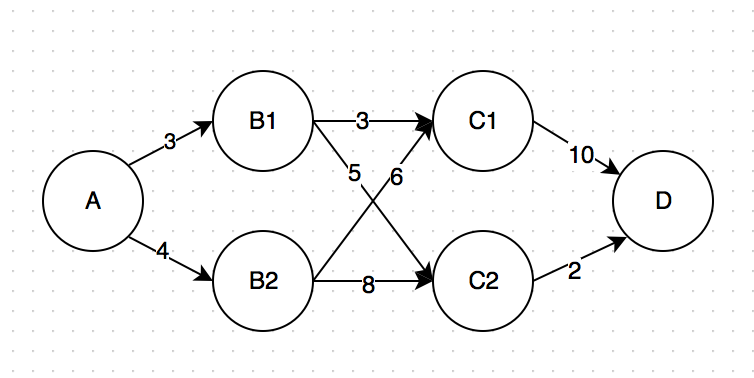
假设如同上图所示,我希望从A走到D,其中各条路径的长度已经标注在图上。那么最短的路径是哪条呢?
最笨的办法,我们可以把每条路径都列出来,一个一个走一遍呗。这里的可能性就是
- A -> B1 -> C1 -> D: 3+3+10 = 16
- A -> B1 -> C2 -> D:3+5+2 = 10
- A -> B2 -> C1 -> D:4+6+10 = 20
- A -> B2 -> C2 -> D:4+8+2=14
所以很显然,最短路径是第二条:A -> B1 -> C2 -> D。
那么如果问题再复杂一点呢?
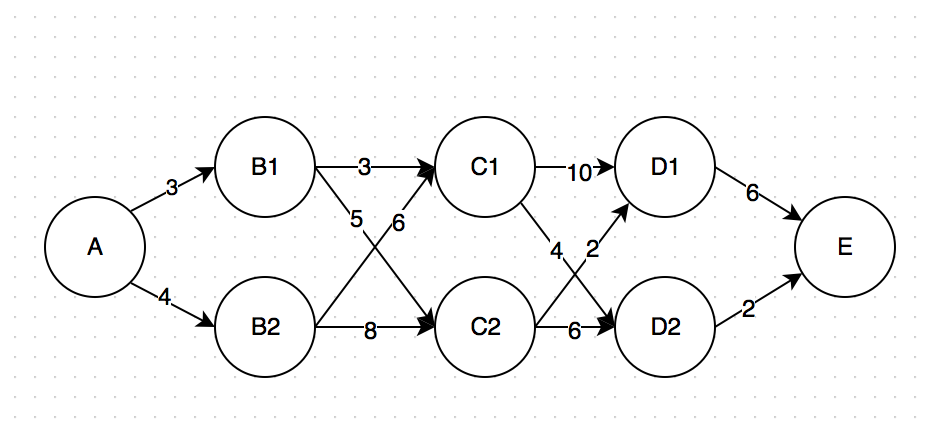 这里我们还是可以继续采用笨办法,只是可能的路径多了一点:
这里我们还是可以继续采用笨办法,只是可能的路径多了一点:
- A -> B1 -> C1 -> D1 -> E: 3+3+10+6 = 22
- A -> B1 -> C1 -> D2 -> E: 3+3+4+2 = 12
- A -> B1 -> C2 -> D1 -> E:3+5+2+6 = 16
- A -> B1 -> C2 -> D2 -> E:3+5+6+2= 16
- A -> B2 -> C1 -> D1 -> E:4+6+10+6 = 26
- A -> B2 -> C1 -> D2 -> E:4+6+6+2 = 18
- A -> B2 -> C2 -> D1 -> E:4+8+2+6 = 8
- A -> B2 -> C2 -> D2 -> E:4+8+6+2 = 20
所以很显然,第二条胜出。在这个过程中我们一共计算了8条路径、24次加法。有没有发现什么规律呢?我们其实有很多重复的计算:比如C1 -> D1 -> E我们计算了两遍。总结一下:
- 不管我们是怎么走到C1的,从C1到最后终点E的最短路径一定是C1 -> D2 -> E,距离为6。同理,不管我们怎么走到C2的,从C2到E怎么走都是8的距离。
- 这样,继续往前推,不管我们是怎么走到B1的,若是从B1到C1再到E,最短距离就是3+6= 9 (C1 -> D1 -> E);若是从B1到C2再到E,最短距离就是5+8=13,所以从B1到E的最短距离就是9。同理,不管我们怎么到B2的,从B2到E的最短距离是 6+6<8+8,故为12。
- 那么回到最初的起点,A到B1再到E,最短距离就是3+9=12;A到B2再到E,最短距离就是4+12=16。
所以在这个过程中,每一步其实我们只进行局部计算就好了,不需要把各种可能性都列出来。下面是我们在每一步可以排除的路径。
- A -> B1 ->
C1 -> D1 -> E: - A -> B1 -> C1 -> D2 -> E: 3+3+4+2 = 12
- A ->
B1 -> C2-> D1 -> E: - A ->
B1 -> C2-> D2 -> E: - A -> B2 ->
C1 -> D1 -> E: - A -> B2 -> C1 -> D2 -> E:4+6+6+2 = 18
- A ->
B2 -> C2-> D1 -> E: - A ->
B2 -> C2-> D2 -> E:
这就是动态规划的力量了:在我们这个例子中,我们可以倒推出来,给定某一步的各种可能性、后面的最优走法。然后这样每次前面的只需要对比怎么走下一步、后面的最优路径就已经计算好了。
这大概是我自己对动态规划最直观的理解了:每一步都是相对独立的,所以可以先不管前面的、针对后面的进行优化、然后慢慢往前推。因为只要到了某步、后面的结果其实并不取决于是怎么到当前步的。
斐波那次数列的动态规划解法
然后看一下最著名的斐波那次数列好了,就是那个著名的数兔子数列:第一年没有兔子,第二年一只兔子,第三年1一只兔子,第四年2只兔子,第五年3只兔子,第六年5只兔子...每次都是前两年的兔子的和。
这个例子是绝佳的演示为什么动态规划体现了用空间换时间。比如我们要算第10年几只兔子,然后上面已经算好了直到第6年的兔子。我们先来看一种最笨的算法。括号里面的数字是倒推出来写的。
第十年的兔子 = 第八年的兔子(5+5+3)+第九年的兔子(5+5+3+5+3)
第九年的兔子 = 第八年的兔子 (5+5+3)+ 第七年的兔子(5+3)
第八年的兔子 = 第六年的兔子 (5)+ 第七年的兔子 (5+3)
第七年的兔子 = 第六年的兔子(5) + 第五年的兔子(3)
.....
一直算下去的话,为了算第10年的兔子,我们要算7次加法。这个过程中可以看出来,除了第五年和第六年的兔子是已知的之外,我们算了两遍第七年的兔子、两遍第八年的兔子、一遍第九年的兔子,然后才算出来第十年的兔子,显然是重复计算。
那动态规划这里怎么用呢?很简单啊,算过的我们就存起来,然后下一次再问到就不用算了呗;没算过的就现算呗。同样,我们已知的是{第一年,0},{第二年,1},{第三年,1},{第四年,2},{第五年,3},{第六年,5}。
所以这个过程就是:
- 为了算第十年的,我需要知道第八年的和第九年的,然后这俩都要算。
- 为了算第九年的,我需要知道第七年的和第八年的,然后这俩都要算。
- 为了算第八年的,我需要知道第七年的和第六年的,然后第七年要算。
- 为了算第七年的,我需要知道第六年的和第五年的,这俩都知道,所以第七年是8。
- 这样,第八年的就是8+5=13。
- 这样,第九年就是8+13 = 21。
- 这样,第十年就是,13+21=34。
于是,每一年我只算了一遍,算好了就存起来了,下次备用就好了。
于是有童鞋说,另外一种办法就是从头到尾算就好了嘛、一个一个往后算、到了第10年停就是了。其实这样从前往后和刚才倒推+存储是一摸一样的计算过程、每一年只算了一遍。因为有存储的存在、动态规划会极大降低时间复杂度。不过显然最省内存的就是从头往后算了,因为我只需要记住n-1和n-2两年的兔子就可以了,不需要知道再往前的年份的。这又体现了一种相对独立的感觉:给定n-1和n-2,n跟n-3...等等就完全没关系了,想想这不就是类似时间序列中的AR(2)过程嘛!
<不过话说最高效的算法,还是通项公式吧,直接就出结果了。但那个就跟这里没关系了呢。>
强盗问题的动态规划解法
最后再来俩个比较好玩的问题吧。House Robber problem,直接复制一下别人的翻译:
你是一名专业强盗,计划沿着一条街打家劫舍。每间房屋都储存有一定数量的金钱,唯一能阻止你打劫的约束条件就是:由于房屋之间有安全系统相连,如果同一个晚上有两间相邻的房屋被闯入,它们就会自动联络警察,因此不可以打劫相邻的房屋。
给定一列非负整数,代表每间房屋的金钱数,计算出在不惊动警察的前提下一晚上最多可以打劫到的金钱数。
我们先来看一下简单的情况。
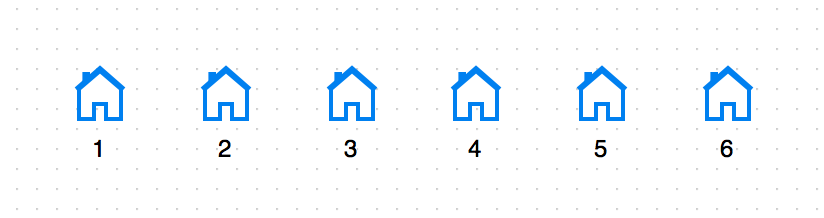 如图,这条街上一共有6栋房子,我们假设它们依次有1-6块钱。然后可行的打劫策略有:
如图,这条街上一共有6栋房子,我们假设它们依次有1-6块钱。然后可行的打劫策略有:
- 打劫1
- 打劫3
- 打劫5: 1+3+5=9
- 打劫6: 1+3+6 =10
- 打劫4
- 打劫6: 1+4+6=11
- 打劫3
- 打劫2
- 打劫4
- 打劫6: 2+4+6 = 12
- 打劫5: 2+5 = 7
- 打劫4
所以简单计算可知,2,4,6是最佳打劫策略。在这个过程中有没有什么熟悉的感觉?比如,给定打劫4,最优的策略一定是打劫6;给定打劫3、最优的策略已经是打劫6。所以我们可以一步步倒推出来、给定某个点、往后最优策略是什么,然后往前慢慢比较前一步怎么走到这个点就可以了。其实无非就是另外一个最短(长)路径问题。
那大致思路就是:已知第i步最优策略,那么只需要比较从i-2走过来和i-3走过来哪个更优就可以了。而我们又知道,这个过程可以借助存储表来降低时间复杂度,而借助存储和从头到尾算又是等价的,所以如果采取从头到尾写的话,就是上面链接给出的代码了:
状态转移方程:
dp[i] = max(dp[i - 1], dp[i - 2] + num[i - 1])
其中,dp[i]表示打劫到第i间房屋时累计取得的金钱最大值。
时间复杂度O(n),空间复杂度O(n)
直白的讲,就是第i步的累积最大值是比较 第i-1步的累积最大值(此时不打劫i) 和 第i-2步累积最大值+第i步金钱(此时打劫i)。
类似的还有一个好玩的问题:
如果这些房子是相互连城圈的,就是第1间和最后一间连在一起,那么就不能同时打劫第1间和最后一间了,此时的最优策略是什么?
答案无非就是,把一个list分别去掉头保留尾、去掉尾保留头,然后分别算一遍动态规划,看看哪个是最优的就可以了。
今天就写到这里吧,希望日后回头看自己还能看得懂...
