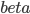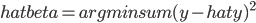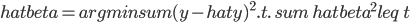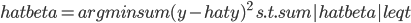随便写写,随便看看。
1. 关于研究方向。
读的paper多了,发现大多数人的研究路数无非两种:
- 一种是锚定一个问题,然后用尽各种办法来看哪种可解。换个通俗的就是,车坏了,找出一堆工具来看看怎么可以修好。
- 另一种则是,沿袭一套方法论的路数,试图解决越来越多的问题。通俗的讲,就是木工不满足于打打家具,还要去试试电工水工装修工。
你说孰优孰劣?没有高下之分。谁也说不好一篇好的研究到底是问题导向的还是方法论导向的。不过鉴于一般来讲方法论比较容易训练出来,所以有的时候看似包装的很漂亮的paper可能正是这个方法灵了然后倒回头来包装问题本身。
本以为这个只是看paper时候的感觉。后面发现,工作其实也不外乎如此。有的人凭着一门专业技能,比如编程,就可以在不同部门之间切换来切换去,反正总有需要用到编程的地方。有的人有一些具体问题,然后就广撒网找来各种背景的人帮忙解决。前者最后进化为技术专家,后者进化为大BOSS。
2. 关于建模
说到模型,反正上来都是那句至理名言:
没有模型是正确的,只有一些是有用的。
所以一切试图证明自己是真理的模型都是无用功。如果是真理,搞成体系那就叫他理论,可以慢慢证明就叫做定理,不证自明那就叫公理好了。反正我觉得说某个模型是正确的这种言论都是挺无聊的。
基于这一条,在实际商业环境中建模,就不要一开始给自己摆太高的期望。就跟上面说的,很多时候问题都是第一类人发现的,他们只是寻求有着不同技能的第二类人帮忙看一下,实践中谁好用就用谁。所以一群第二类人内部争来争去,什么机器学习流派啊、数理统计流派啊、计量帮啊、物理统计帮啊还是算命仙人这些其实都不那么重要...比如最近世界杯大家都在预测,那么不管你是章鱼还是小丸子还是霍金,只有预测对了大家才信你。
所以在学校里被某个流派洗脑洗的深入骨髓的,可以醒醒了。不要一上来就摆出自己是真理这样的架势。每个人在象牙塔里都是这么教的。
3. 关于统计建模
如果大家笃定就要用统计的方法了,那么要解决的问题就无非是:搜集数据(变量)、选择模型、修改参数以达到最优。
具体到项目,搜集数据这个肯定是大头。每个学过统计的都被教导过“garbage in, garbage out”。只可惜大部分老师讲完这句话之后,学生并没有多少机会实际的去搜集数据,或者更直接的去想要怎么搜集数据。大部分学校里面的训练(尤以网上数据挖掘竞赛之时)都是,数据集给定,怎么找个更好的模型来预测/评估/解释。真到了项目上需要搜集数据了,大部分人的做法无非就是先找张纸把想到的变量都分门别类列出来,然后把所有可能拿到的数据都扔进去试试,从简单的线性回归或者分类器开始,到非线性的各种模型都扔进去跑一遍,反正这年头计算能力不是瓶颈,总有合适的模型自己可以去做变量选择。
听到这里,貌似也挺好啊。是啊确实没什么不好,如果大家都有充足的时间慢慢玩的话。可惜的就是这种无脑流在大多数情况下都是受制约于时间的。于是为了省时间,要么就某些麻烦的数据不搜集了,要么就某些计算复杂的模型不去跑了。差不多就好了。解决问题了么?可能也差不多解决了70%-80%。
与此同时还有一类业务流派。这类人特别像医生似的,是某个具体领域的专家,专到什么程度呢?基本上他熟悉的地儿有个风吹草动都逃不过他的眼睛。直觉很准,或者说经验实在是太丰富了。跟这个流派的人一起工作很好玩,他们想到一个问题大概的给你指一个方向,大部分情况下八九不离十,差不多就可以把问题解决了。就算事后需要稍微建建数理模型多做一些分析和验证,基本也不会太麻烦。每当此时,不禁大呼一声畅快,瞬间觉得自己以前的思路真实的麻烦爆了。嗯,爽归爽,不过这种流派需要在一个领域浸淫比较长的时间,逃出他的领域就比较难说了。
4. 关于这些碎碎念
基本上就是想说,容易训练出来的都是不重要的...那些东西都进化很快,学术界不是白白养了一群人浪费的(虽然也挺浪费的),所以长江后浪一定会把前浪拍死在沙滩上。
与此同时,业务知识也不是那么重要的。经济环境变化太快,谁也不知道明天这个世界会变成什么样子。
那既然都是以不变应万变,那还是选一条比较开心的路子。总是需要合作的,这个世界已经复杂到没有可以一个人解决的问题了。