今天闲着无聊抓了一下NBER最近一年的working paper数据看看。众所周知,econ现在发表周期越来越长,一两年都算少的,三五年也挺常见的。虽然跟跟AER什么的也是个比较好的指向,但多少还是“旧”了一点。
NBER覆盖的研究范围还是蛮广的,大部分发表的paper都能在这里找到working paper版本,所以一时没想到更好的抓数据的来源:
Aging(AG)
Asset Pricing(AP)
Children(CH)
Corporate Finance(CF)
Development Economics(DEV)
Development of the American Economy(DAE)
Economics of Education(ED)
Economic Fluctuations and Growth(EFG)
Environmental and Energy Economics (EEE)
Health Care(HC)
Health Economics(HE)
Industrial Organization(IO)
International Finance and Macroeconomics(IFM)
International Trade and Investment(ITI)
Labor Studies(LS)
Law and Economics(LE)
Monetary Economics(ME)
Political Economy(POL)
Productivity, Innovation, and Entrepreneurship Program(PR)
Public Economics(PE)
抓了一番之后,基本关键词热度如下。一些太没有意义的我就调透明了。(个人很讨厌word cloud这种东西,所以还是选择了bar chart)
[3/19更新] 和Bing里面的key words match了一下。貌似信息多了一些。
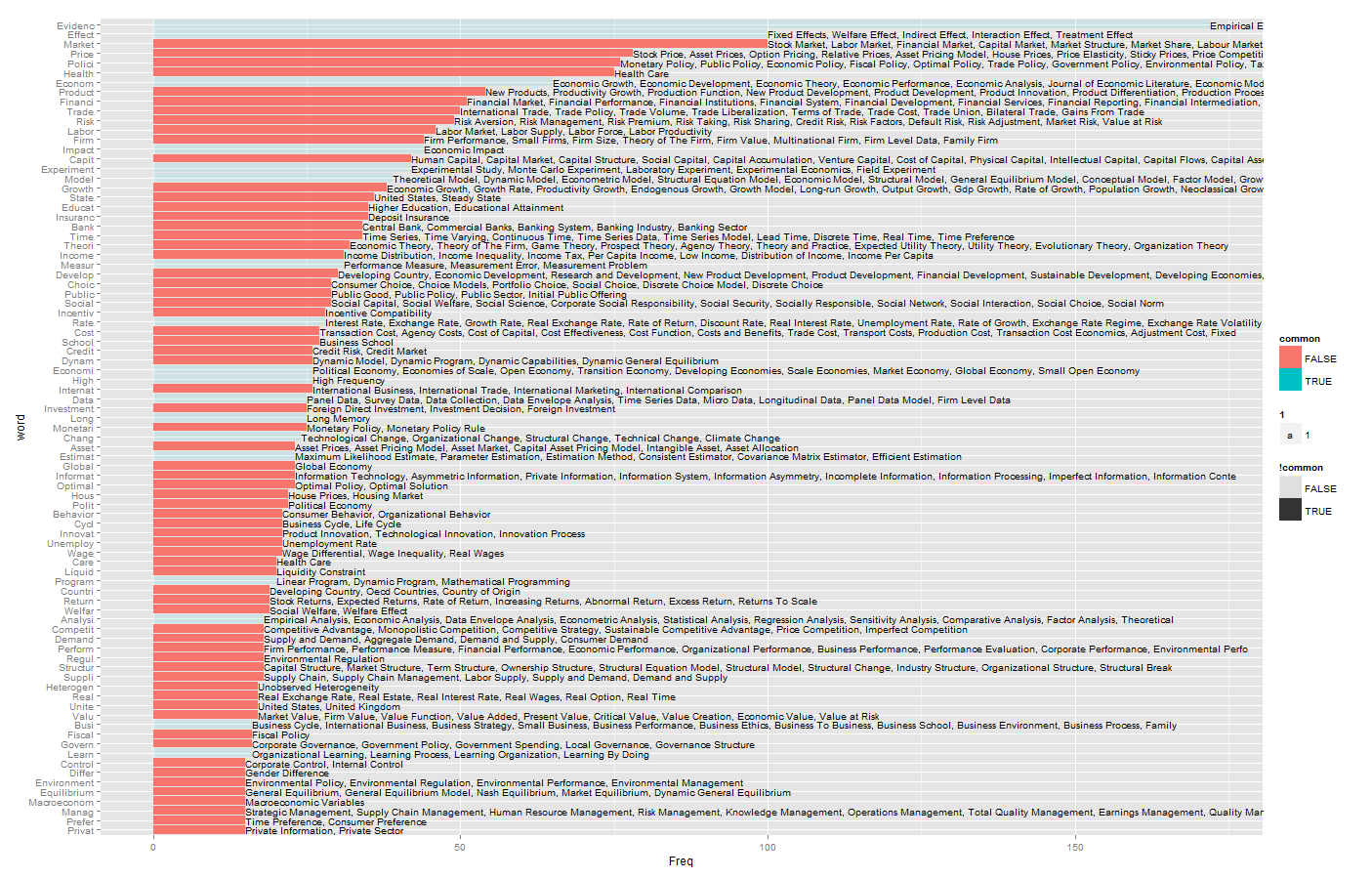
虽然数目不代表质量,但至少能看出来有多少人在某个领域耕耘。最突出的就是health这里了,很高(钱很多)。然后还有很多研究trade和growth的。然后risk和finance好像也蛮多的,crisis好像也挺多。Labor和IO一直也是热热的。研究方法上,随机试验还是最亮的。
没有进一步分析那些作者在高产,下次搞个“抱大腿”趋势好了。
代码在这里:
grab_url <- c("http://www.nber.org/new_archive/mar14.html",
"http://www.nber.org/new_archive/dec13.html",
"http://www.nber.org/new_archive/sep13.html",
"http://www.nber.org/new_archive/jun13.html",
"http://www.nber.org/new_archive/mar13.html")
library(RCurl)
require(XML)
grab_paper <- function (grab) {
webpage <- getURLContent(grab)
web_content <- htmlParse(webpage,asText = TRUE)
paper_title <- sapply(getNodeSet(web_content, path="//li/a[1]"),xmlValue)
author <- sapply(getNodeSet(web_content, path="//li/text()[1]") ,xmlValue)
paper_author <- data.frame(paper_title = paper_title, author = author)
return(paper_author)
}
library(plyr)
paper_all <- ldply(grab_url,grab_paper)
titles <- strsplit(as.character(paper_all$paper_title),split="[[:space:]|[:punct:]]")
titles <- unlist(titles)
library(tm)
library(SnowballC)
titles_short <- wordStem(titles)
Freq2 <- data.frame(table(titles_short))
Freq2 <- arrange(Freq2, desc(Freq))
Freq2 <- Freq2[nchar(as.character(Freq2$titles_short))>3,]
Freq2 <- subset(Freq2, !titles_short %in% stopwords("SMART"))
Freq2$word <- reorder(Freq2$titles_short,X = nrow(Freq2) - 1:nrow(Freq2))
Freq2$common <- Freq2$word %in% c("Evidenc","Effect","Econom","Impact","Experiment","Model","Measur","Rate","Economi",
"High","Data","Long","Chang","Great","Estimat","Outcom","Program","Analysi","Busi"
,"Learn","More","What")
library(ggplot2)
ggplot(Freq2[1:100,])+geom_bar(aes(x=word,y=Freq,fill = common,alpha=!common))+coord_flip()
### get some keywords from Bing academic
start_id_Set = (0:5)*100+1
require(RCurl)
require(XML)
# start_id =1
#
get_keywords_table <- function (start_id) {
end_id = start_id+100-1
keyword_url <- paste0("http://academic.research.microsoft.com/RankList?entitytype=8&topDomainID=7&subDomainID=0&last=0&start=",start_id,"&end=",end_id)
keyword_page <- getURLContent(keyword_url)
keyword_page <- htmlParse(keyword_page,asText = TRUE)
keyword_table <- getNodeSet(keyword_page, path="id('ctl00_MainContent_divRankList')//table")
table_df <- readHTMLTable(keyword_table[[1]])
names(table_df) <- c("rowid","Keywords" , "Publications" ,"Citations")
return (table_df)
}
require(plyr)
keywords_set <- ldply(start_id_Set,get_keywords_table)
save(keywords_set, file="keywords_set.rdata")
最后更新的部分代码。效率偏低,见谅。
### map keywords
load("keywords_set.rdata")
load("NBER.rdata")
keys <- strsplit(as.character(keywords_set$Keywords), split=" ")
require(SnowballC)
keys_Stem <- lapply(keys,wordStem)
#get edges
edge_Set <- data.frame()
for (word in Freq2$word){
# print(word)
for (key_id in 1:length(keys_Stem)){
# print(keys_Stem[[key_id]])
if (word %in% keys_Stem[[key_id]]) {
edge <- data.frame(keywords = keywords_set[key_id,]$Keywords, kid = word)
edge_Set <- rbind(edge_Set,edge)}
}
}
#edge_Set
require(ggplot2)
kid_freq <- as.data.frame(table(edge_Set$kid))
require(plyr)
kid_freq <- arrange(kid_freq, desc(Freq))
edge_Set_sub <- subset(edge_Set, kid %in% Freq2[1:100,]$word)
edge_Set_sub$keywords <- as.character(edge_Set_sub$keywords)
# edge_Set_sub$kid <- as.character(edge_Set_sub$kid)
link_keys <- function(x) {paste(x$keywords,collapse = ", ")}
linked <- ddply(edge_Set_sub, .(kid), link_keys)
show_keys <- merge(Freq2[1:100,],linked, by.x="word",by.y="kid", all.x=T)
names(show_keys)[5] <- "linked"
ggplot(show_keys[!is.na(show_keys$linked),],aes(x=word,y=Freq))+
geom_bar(aes(fill = common,alpha=!common),stat="identity",ymin=10)+coord_flip()+
geom_text(aes(label=substr(linked,1,200),y = Freq, size = 1),hjust=0)